
Python/크롤링(Crawling)
파이썬(1)-Crawling, Scraping
두설날
2024. 5. 20. 09:34

*이 글을 읽기전에 작성자 개인의견이 있으니, 다른 블로그와 교차로 읽는것을 권장합니다.*
1. 크롤링과 스크랩핑
- 크롤링(Crawling): 인터넷의 데이터를 활용하기 위해 정보들을 분석하고 활용할 수 있도록 수집하는 행위
- 스크랩핑(Scraping): 크롤링 + 데이터를 추출하고 가공하는 행위, 다만 법적인 판단에 의거해서 저작권 허용이 가능한 것만.
2. request, BeautifulSoup 모듈
// requests 모듈: http 요청을 위해 사용하는 모듈, 파이썬에서 router요청방식(미들웨어)를 사용할 때,
// 매개체로 사용하는 메서드입니다.
import requests
// BeautifulSoup 모듈: 웹 브라우저에서 구문 분석(parsing) 및 scraping에 활용하는데 필요한 모듈
from bs4 import BeautifulSoupsite = 'https://basicenglishspeaking.com/daily-english-conversation-topics/'
request = requests.get(site)
print(request) #Response[200]은 라우터 접속성공
# print(request.text) #html,css,javascript를 볼 수 있음데이터 수집 연습 사이트:https://basicenglishspeaking.com/daily-english-conversation-topics/
(75 Audio Lessons) Daily English Conversation Practice | Questions and Answers By Topics
Daily English Conversation Practice - Questions and Answers by TopicYou have troubles making real English conversations? You want to improve your Spoken English quickly? You are too busy to join in any English speaking course?Don’t worry. Let us help you
basicenglishspeaking.com
#html.parser가 default값이므로, 생략가능
soup = BeautifulSoup(request.text)
print(soup)BeautifulSoup로 requests.get('해당사이트')를 출력한다면 scraping 할 수 있습니다.
# a 선택자만 배열(파이썬이니까 리스트)형태 가져오기
links = divs.findAll('a')
print(links)findAll메서드를 사용하여 html속성 중 해당 선택자만 선택하여 출력할 수 있습니다.
# links집합에서 <a></a>안에 들어있는 text 가져오기
for link in links:
print(link.text)// 리스트 안에 가져오기
subject = []
# subject 리스트에 link.text추가
for link in links:
subject.append(link.text)
subject# subject의 전체갯수
len(subject)print('총', len(subject),'개의 주제를 찾았습니다')
for i in range(len(subject)):
print('{0:2d}, {1:s}'.format(i+1, subject[i]))
#d는 decimal, s는 string을 의미함. {0:2d}에서 0은 indent를 0 설정, 2d는 출력 글씨체의 최소 너비와 타입을 의미.
# {1:s}에서 1은 indent=1설정, s는 타입설정3. 다음뉴스 제목 스크래핑
#https://v.daum.net/v/20240520095642591
#https://v.daum.net/v/20240519230450112
#해당site를 객체로 전달하고 get방식으로 미들웨어 라우터(객체2) 연결
#BeatifulSoup함수로 html요소 가져와서 그중에서 특정 원소의 선택자만 출력
def daum_news_title(new_id):
url = 'https://v.daum.net/v/{}'.format(new_id)
request = requests.get(url)
soup = BeautifulSoup(request.text)
title= soup.find('h3', {'class', 'tit_view'})
if title:
return title.text.strip()
return '제목없음'daum_news_title('20240520095642591')
daum_news_title('20240519230450112')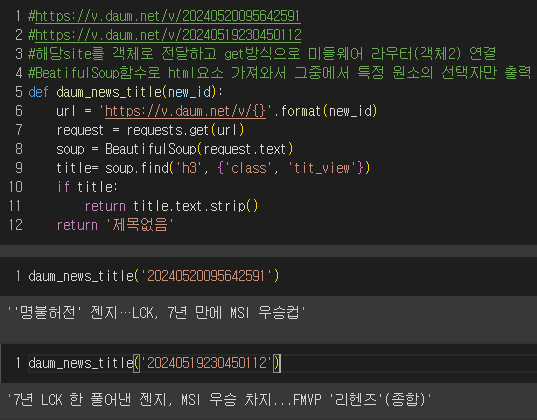
4. 벅스 뮤직 차트 가져오기
# 1위 Supernova - aespa
# 2위 해야 (HEYA) - IVE (아이브)
# <p>로 text 뽑기
# requests는 import모듈, BeautifulSoup도 모듈
request = requests.get('https://music.bugs.co.kr/chart')
soup = BeautifulSoup(request.text
// BeautifulSoup에서 class이름이 title인 p 태그 가져오기
titles= soup.findAll('p', {'class':'title'})
# print(titles)
// BeautifulSoup에서 class이름이 artist인 p 태그 가져오기
artists = soup.findAll('p', {'class':'artist'})
# print(artists)# strip()함수? 문자타입 공백, 특수문자 제거
# enumerate()함수? 인덱스와 값을 동시에 반환
for i, (t,a) in enumerate(zip(titles, artists)):
title = t.text.strip()
artist = a.text.strip().split('\n')[0]
print('{0:3d}위, {1:s} - {2:s}'.format(i+1, title, artist))

5. 멜론 차트 가져오기
robots.txt: 웹 사이트에 크롤러같은 로봇들의 접근을 제어하기 위한 규약
request = requests.get('https://www.melon.com/chart/index.htm')
print(request)#<Response [406]> 라우터 파싱 불가
# f12- network - F5 - index.htm - User-Agent:
# Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)
header = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'}
url = 'https://www.melon.com/chart/index.htm'
request = requests.get(url, headers=header)
print(request)
soup = BeautifulSoup(request.text)
titles = soup.findAll('div', {'class':'ellipsis rank01'})
# print(titles)
artists = soup.findAll('div', {'class':'ellipsis rank02'})
#print(artists)
for i, (t, a) in enumerate(zip(titles, artists)):
title = t.span.text.strip()
artist = a.span.text.strip()
print('{0:3d}위. {1:s} - {2:s}'.format(i+1, title, artist))
6. 네이버 증권에서 이름, 가격, 종목코드, 거래량 가져오기
# https://finance.naver.com/item/main.naver?code=032800
# https://finance.naver.com/item/main.naver?code=053950
# 이름, 가격, 종목코드, 거래량
# {'name': '경남제약', 'price': '1545', 'code': '053950', 'volumn':'1828172'}
# 라우터 확인
site ='https://finance.naver.com/item/main.naver?code=053950'
request = requests.get(site)
print(request)
soup = BeautifulSoup(request.text)
div_totalinfo = soup.find('div', {'class':'new_totalinfo'})
# print(div_totalinfo)def naver_finance(code):
# 사이트 가져오기
site=f'https://finance.naver.com/item/main.naver?code={code}'
# 라우터 req
request = requests.get(site)
# parsing
soup=BeautifulSoup(request.text)
# 전체
div_totalinfo = soup.find('div', {'class':'new_totalinfo'})
# 이름
name = div_totalinfo.find('h2').text
# 가격
div_today=div_totalinfo.find('div',{'class':'today'})
price=div_today.find('span',{'class':'blind'}).text
# 코드
div_description = div_totalinfo.find('div', {'class':'description'})
code = div_description.find('span',{'class': 'code'}).text
# 거래량
table_no_info = soup.find('table',{'class':'no_info'})
tds = table_no_info.findAll('td')
volume = tds[2].find('span',{'class':'blind'}).text
# 출력형태
dic = {'name': name, 'price': price, 'code': code, 'volumne': volume}
return dicprint(naver_finance('053950'))
naver_finance('032800')
codes = ['053950', '032800', '001440', '005930', '003230']
data = []
for code in codes:
dic = naver_finance(code)
data.append(dic)
print(data)
+ pandas로 dataframe형태로 가져오기
import pandas as pd
df = pd.DataFrame(data)
df
# 엑셀 파일 변환
df.to_excel('naver_finance.xlsx')
과제:
- 지니뮤직
- https://www.genie.co.kr/chart/top200
- https://www.genie.co.kr/chart/top200?ditc=D&ymd=20240520&hh=12&rtm=Y&pg=1
- https://www.genie.co.kr/chart/top200?ditc=D&ymd=20240520&hh=12&rtm=Y&pg=2 for문으로 그냥 돌려버리면 잘 안나옴. 따라서 슬립기능 활용해서 다시 for문 돌려서 가져오기 과제는 GitHub repository로 넣어두기