Python/크롤링(Crawling)
파이썬(4)-pixabay
두설날
2024. 5. 23. 11:15

*이 글을 읽기전에 작성자 개인의견이 있으니, 다른 블로그와 교차로 읽는것을 권장합니다.*
1. 특정 키워드를 검색해서 화면이 나오면 이미지 선택하기
!pip install selenium
!pip install chromedriver_autoinstaller
import chromedriver_autoinstaller
import time
from selenium import webdriver
from urllib.request import Request, urlopen
driver = webdriver.Chrome()
def search(word):
url = 'https://pixabay.com/ko/images/search/' + word
driver.get(url)
search('winter')image_xpath = '/html/body/div[1]/div[1]/div/div[2]/div[3]/div/div/div/div[23]/div/a/img'
image_url = driver.find_element('xpath', image_xpath).get_attribute('src')
print('image_url: ', image_url)image_byte = Request(image_url, headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'})
f = open('winter.jpg','wb') # writebyte 모드로 만듦
f.write(urlopen(image_byte).read()) # 이게 들어있는 파일에 이미지가 저장
f.close()픽사베이 한 화면에 있는 사진 모두 다운하기 for문, time 사용
url = f'https://pixabay.com/ko/images/search/고양이'
driver = webdriver.Chrome()
driver.get(url)image_xpath = '/html/body/div[1]/div[1]/div/div[2]/div[3]/div/div'
image_url = driver.find_element('xpath', image_xpath).get_attribute('src')
print(image_url.find_elements)2. 여러개 이미지 수집하기
import chromedriver_autoinstaller
import time
from selenium import webdriver
from urllib.request import Request, urlopen
from selenium.webdriver.common.by import Bydriver = webdriver.Chrome()
word = 'winter'
url = 'https://pixabay.com/ko/images/search/' + word
driver.get(url)
driver.implicitly_wait(2) # (페이지 다부르기위한 용도)3초 기다리고 다음으로
# for _ in range(20):
# driver.execute_script("window.scrollBy({ top: window.innerHeight, behavior: 'smooth' })")
# driver.execute_script(f'window.scrollTo(0, document.body.scrollHeight/({i}+1))')
# time.sleep(0.5)
for i in range(20):
driver.execute_script(f'window.scrollTo(0, 1000 * {i})')
time.sleep(0.1)
image_area_xpath = '/html/body/div[1]/div[1]/div/div[2]/div[3]/div/div'
image_area = driver.find_element(By.XPATH, image_area_xpath)
image_elements = image_area.find_elements(By.TAG_NAME, 'img')
image_urls = []
for image_element in image_elements:
image_url = image_element.get_attribute('src')
print(image_url)
image_urls.append(image_url)import os
from urllib import parse
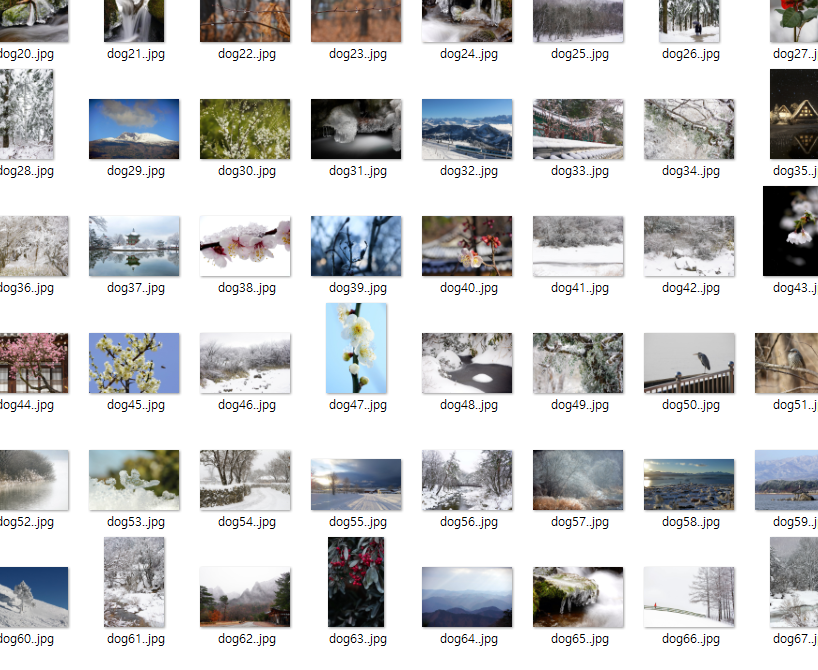
# 0번~99번까지 강아지사진 저장 완료
for i in range(len(image_urls)):
image_url = image_urls[i]
url = parse.urlparse(image_url)
name, ext = os.path.splitext(url.path) #path='/photo/2017/09/25/13/12/puppy-2785074_1280.jpg', params='', query='', fragment='')
image_byte = Request(image_url, headers= {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'})
f = open(f'dog{i}.{ext}', 'wb')
f.write(urlopen(image_byte).read())
f.close()3. 함수로 리팩토링
- crawl_and_save_image(keyword, pages)
- 강아지 이름으로 폴더 만들고, keyword이름으로 사진 넣기
import chromedriver_autoinstaller
import time
from selenium import webdriver
from urllib.request import Request, urlopen
from selenium.webdriver.common.by import By
import os
from urllib import parse
def searching(word):
driver = webdriver.Chrome()
url = 'https://pixabay.com/ko/images/search/' + word
driver.get(url)
driver.implicitly_wait(2)
def crawl_and_save_image(keyword, pages):
image_urls = []
for i in range(1, pages+1):
url = f'https://pixabay.com/ko/images/search/{keyword}/?pagi={i}'
driver.get(url)
driver.implicitly_wait(2)
time.sleep(2)
for i in range(20):
driver.execute_script(f'window.scrollTo(0, document.body.scrollHeight / 20 * {i})')
time.sleep(0.1)
image_area_xpath = '/html/body/div[1]/div[1]/div/div[2]/div[3]/div/div'
image_area = driver.find_element(By.XPATH, image_area_xpath)
image_elements = image_area.find_elements(By.TAG_NAME, 'img')
for image_element in image_elements:
image_url = image_element.get_attribute('src')
print(image_url)
image_urls.append(image_url)
if not os.path.exists(keyword):
os.mkdir(keyword)
print(len(image_urls))
# for i in range(len(image_urls)):
# image_url = image_urls[i]
# filename = image_url.split('/')[-1]
# image_byte = Request(image_url, headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'})
# f= open(f'{keyword}/{filename}', 'wb')
# f.write(urlopen(image_byte).read())
# f.close()driver = webdriver.Chrome()
# 사진 폴더안에 저장
crawl_and_save_image('tiger',2)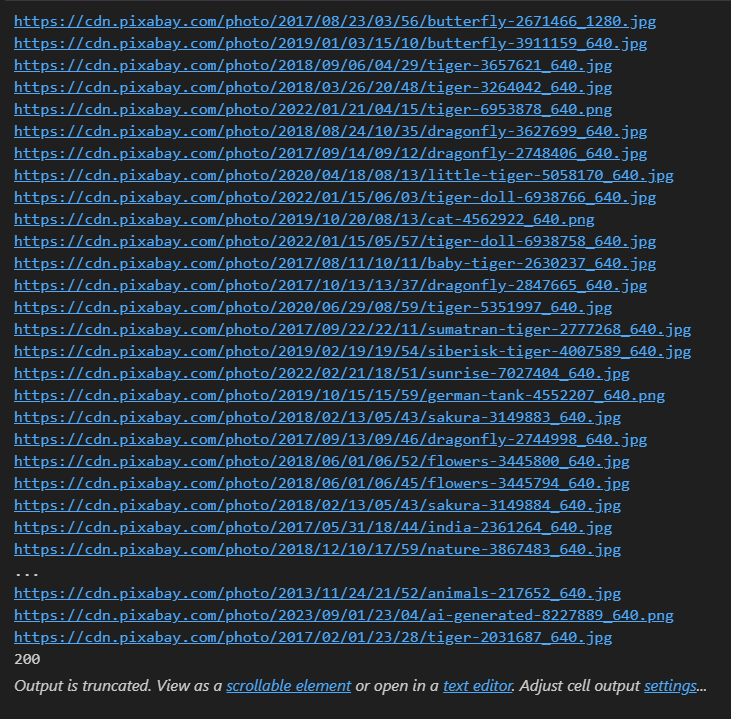
f.close()