파이썬(6)-Pandas(1)

*이 글을 읽기전에 작성자 개인의견이 있으니, 다른 블로그와 교차로 읽는것을 권장합니다.*
1. 판다스(Pandas)
데이터 분석을 위한 파이썬 라이브러리 중 하나로, 표 형태의 데이터나 다양한 형태의 데이터를 쉽게 처리하고 분석합니다.
특히 테이블 형식의 데이터를 다루는 데 강력한 기능을 제공하며, 데이터 프레임(DataFrame)과 시리즈(Series)라는 두 가지 주요 데이터 구조를 기반으로 동작합니다.
# pip설치
!pip install pandas
# 모듈 연결
import pandas as pd
주요 특징
1-1. 데이터 구조:
- Series: 1차원 배열과 유사한 구조로, 인덱스를 포함한 데이터를 저장합니다.
- DataFrame: 2차원 표 형식의 데이터 구조로, 각 열이 Series 객체로 구성됩니다. 행과 열 모두 인덱스를 가질 수 있습니다.
1-2. 데이터 조작 기능:
- 데이터 선택 및 필터링: 데이터 프레임에서 특정 행이나 열을 선택하고, 조건을 기반으로 데이터를 필터링할 수 있습니다.
- 데이터 정렬: 행이나 열을 기준으로 데이터를 정렬할 수 있습니다.
- 데이터 병합 및 결합: 여러 데이터 프레임을 하나로 병합하거나 결합할 수 있습니다.
1-3. 데이터 변환:
- 결측값 처리: 결측값을 쉽게 확인하고, 제거하거나 대체할 수 있습니다.
- 데이터 형식 변환: 데이터 형식을 다른 형식으로 변환할 수 있습니다.
- 집계 및 그룹화: 데이터를 그룹별로 집계하거나 요약할 수 있습니다.
1-4. 입출력 기능: 다양한 파일 형식(CSV, Excel, SQL 데이터베이스, JSON 등)에서 데이터를 읽고 쓸 수 있습니다.
2. Series와 DataFrame
2-1. Series
Series는 1차원 배열과 같은 자료구조로 하나의 열을 나타냅니다. = 1행 X, 1열 O
Series의 각 요소는 Index와 Value값으로 구성되어 있습니다.
값은 넘파이의 ndarray 기반으로 저장됩니다.
Series는 다양한 데이터 타입을 가질 수 있으며, 정수, 실수, 문자열 등 다양한 형태의 데이터를 담을 수 있습니다.
[Index Value]
idx = ['김사과', '반하나', '오렌지', '이메론', '배애리']
data = [67, 75, 75, 62, 98]
# Series(데이터, 인덱스)
pd.Series(data)
se1 = pd.Series(data, idx)
se1
print(se1.index)
print(se1.values)
2-2. DataFrame
데이터프레임은 판다스 라이브러리에서 제공하는 중요하고 강력한 데이터 구조로 2차원의 테이블 형태 데이터를 다룹니다.
데이터프레임의 각 요소는 Index, Column, Value값으로 구성되어 있습니다.
데이터프레임은 행과 열로 이루어져 있으며, 각 열은 다양한 데이터 타입을 가질 수 있습니다.
Value값은 넘파이의 ndarray기반으로 저장됩니다.
[Index, Column, Value]
data = ([67, 93, 91], [75, 68, 96], [76, 81, 82], [62, 70, 75], [98, 56, 87])
idx = ['김사과', '반하나', '오렌지', '이메론', '배애리']
col = ['국어', '영어', '수학']# DataFrame(데이터, 인덱스, 칼럼, ...)
pd.DataFrame(data)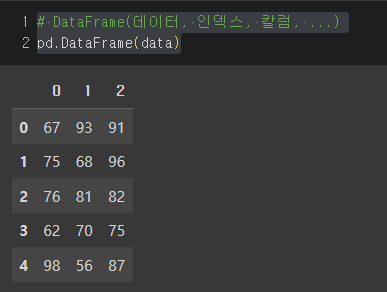
pd.DataFrame(data, idx)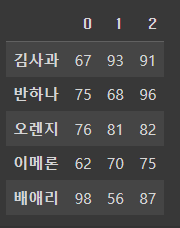
df = pd.DataFrame(data = data, index = idx, columns = col)
df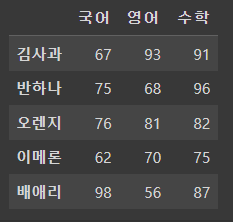
print(df.index)
print()
2-3. 딕셔너리를 사용하여 데이터프레임을 생성하기
dic = {
'국어' : [67, 75, 76, 62, 98],
'영어' : [93, 68, 81, 70, 56],
'수학' : [91,96, 82, 75, 87]
}
# index에 idx객체 넣음
df = pd.DataFrame(data=dic, index=idx)
df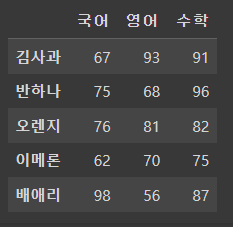
3. CSV 파일 읽어오기
csv(Comma Separated Value)의 약자로, 데이터를 쉼표로 구분한 파일입니다.
df = pd.read_csv('/content/drive/MyDrive/KDT/5. 데이터 분석/데이터/idol.csv')
df
type(df)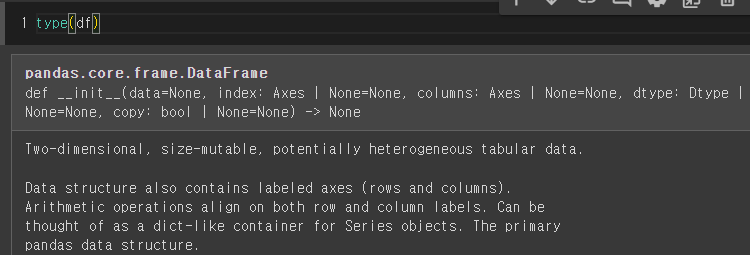
info(): 행, 열의 기본적인 정보와 데이터 타입 반환합니다.
# info(): 행(row), 열(column)의 기본적인 정보와 데이터 타입을 반환
df.info()
# object type은 문자형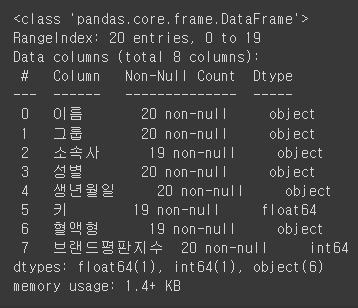
# 칼럼명 변경
print(df.columns)
new_column = ['name', 'group', 'company', 'gender', 'birthday', 'height', 'blood', 'brand']
df.columns = new_column #대입
df
describe(): 통계수치를 반환합니다.
# describe(): 통계 정보(수치)를 반환
#count = 데이터값 갯수, std=표준편차=standard error를 말함.
df.describe()
df.describe(include=object) # top: 최빈값: 가장 자주나오는, freq: 빈도수
# 원하는 갯수와 데이터 보기(5개가 기본값)
df.head()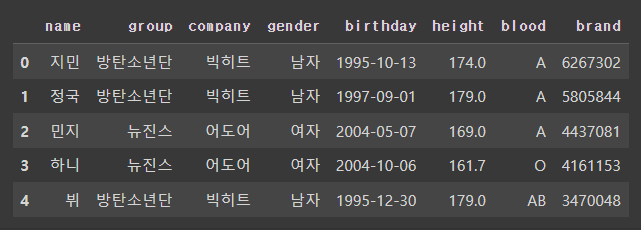
#하위 2개
df.tail(2)
4. 정렬하기
sort_index(): 정렬하기
# sort_index(): 정렬하기
df.sort_index() # index로 오름차순 정렬: 기본값
#오름차순 역순= 내림차순
df.sort_index(ascending=False)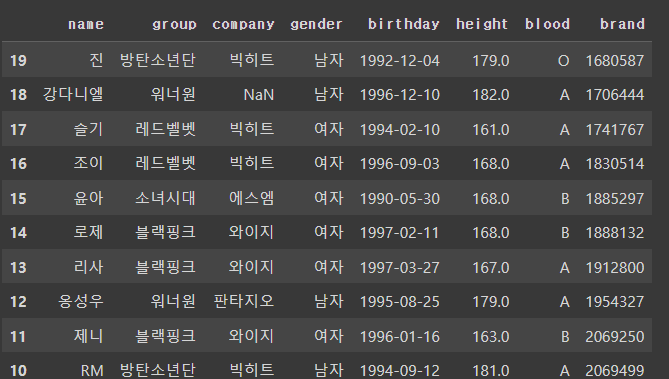
df.sort_values(by='height') #키로 오름차순 정렬. 단, Null값은 항상 맨 밑에 있음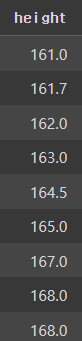
df.sort_values(by='height', ascending=False) #키로 내림차순 정렬
# Null값 위로 올리기
df.sort_values(by='height', ascending=False, na_position='first')
# 키가 동일할 경우, 브랜드평판지수로 내림차순
# 1차 정렬: 키(내림차순), 2차 정렬: 브랜드(내림차순)
# 파이썬은 차수가 늘어나면 리스트(배열)로 묶어서 늘리면 된다.
df.sort_values(by=['height', 'brand'], ascending=[False, False], na_position='first')
5. 데이터 다루기
df.head()
#혈액형 칼럼만 뽑기
df['blood'] # 리스트로 접근
df.blood # 속성으로 접근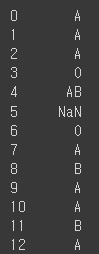
# index 범위 선택
df[:3]
loc() : Pandas 라이브러리에서 데이터프레임(DataFrame)의 특정 행과 열, 라벨을 사용하여 선택하고 조작하는 데 사용하는 인덱싱 메서드
# loc() : Pandas 라이브러리에서 데이터프레임(DataFrame)의 특정 행과 열을 라벨을 사용하여
#선택하고 조작하는 데 사용하는 인덱싱 메서드
# loc 인덱싱: 이름 인덱싱, 행과 열 모두 인덱싱과 슬라이싱이 가능
# df.loc[가져오려는 index범위, 가져오려는 column]
df.loc[0]
df.loc[:, 'name']
# 헷갈리는게 5번을 포함, 이름이 location이기 때문에 지역정보를 가져오기 때문
df.loc[2:5, 'name']
# 2~5번 index의 column 이름, 성별, 키 가져오기
df.loc[2:5, ['name', 'gender', 'height']]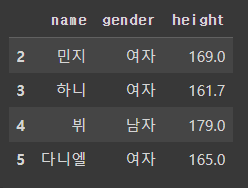
# column name~gender 범위에 해당하는 column 가져오기
df.loc[2:5, 'name':'gender']
# iloc 인덱싱: i는 index, 인덱스로 인덱싱하는 방법, 행과 열 모두 인덱싱과 슬라이싱 가능
# loc[]와 동일하게 df.iloc[가져오는 index범위, 가져오는 column범위]
df.iloc[:,0]
# 0번, 2번 index에 해당하는 column 가져오기
df.iloc[:,[0,2]]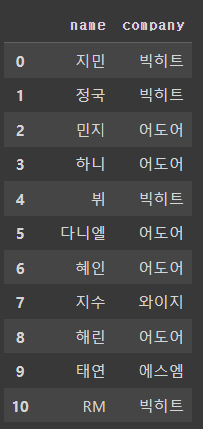
# 2번 column 미포함
df.iloc[:, 0:2]
#1~4, 0~1
df.iloc[1:5, 0:2]
# height칼럼의 value값 boolean연산
df['height'] >= 180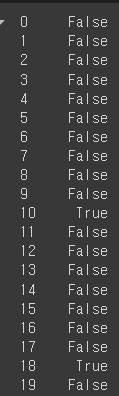
# height>=180 True인 name column만 출력
df['name'][df['height']>=180]
# height>=180 True인 name column만 출력, 위와 동일
df[df['height']>=180]['name']
df[df['height']>=180][['name','gender','height']]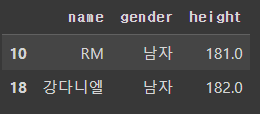
문제
키가 180이상인 연예인의 이름, 성별, 키, 브랜드평판지수를 출력
단, loc를 사용해서
# 앞에 범위를 조건으로, 뒤에는 출력하려는 Column을
df.loc[df['height']>=180, ['name','gender','height','brand']]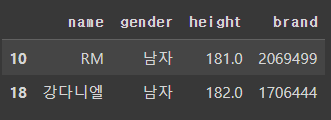
isin(): 정의한 list에 있는 데이터를 비교해서 불린형으로 반환, 비교형으로 사용합니다.
# isin(): 정의한 list에 있는 데이터를 비교해서 불린형으로 반환 -> 범위에서 조건으로 사용
company=['빅히트', '어도어']
df['company'].isin(company)
df[df['company'].isin(company)] #df[df['company'].isin(company), :]
6. 결측값(Null, NaN)
결측값은 비어있는 값, 판다스에서는 NaN(Not a Number)로 표기 된 것은 모두 결측값으로 취급
df.info() #company, height, blood column에 결측값 1개씩 존재O
isna(), isnull(): 결측값 확인
# isna(), isnull(): 결측값 확인
df.isna()
df.isnull()
df['height'].isna()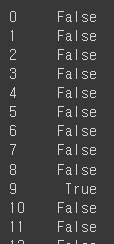
# column height에서 null값인 df 뽑기
df[df['height'].isna()]
# 그중 name column만 뽑기
df[df['height'].isna()]['name']
# height가 null값인 row 제외
df[df['height'].notnull()]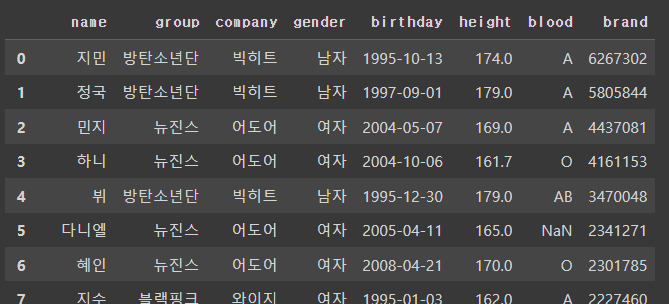
문제
회사가 있는 연예인의 이름, 회사, 키를 출력
단, loc를 사용
df.loc[df['company'].notnull(),['name', 'company', 'height']]
fillna(): 결측값을 채워주는 함수
# fillna(): 결측값을 채워주는 함수
# 데이터에 null값이 너무 많아서, 채워줘야 할때
df['height'].fillna(0) # df['height'].fillna(0, inplace=True) #적용
df_copy = df.copy() #df 복사
df_copyheight = df_copy['height'].mean() #평균
height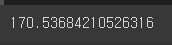
df_copy['height'] = df_copy['height'].fillna(height) #Nan에 평균대입, 저장
df_copy['height']
df_copy = df.copy()
df_copy['height']
median(): 중위값
height = df_copy['height'].median() # 중위값 저장
height
df_copy['height'].fillna(height, inplace=True) # NaN에 중위값 대입
df_copy['height']
df_copy = df.copy()
df_copydropna(): 결측값 행,열 제거, 결측값이 1개라도 있는 경우 제거
# dropna(): 결측값 행,열 제거, 결측값이 1개라도 있는 경우 제거
df_copy.dropna() # axis = 0 행 삭제 생략
# 결측값 있는 열 제거
df_copy.dropna(axis=1)
7. 행, 열 추가 및 삭제하기
행을 추가할 때 dict 형태의 데이터를 만들고 append() 메서드를 사용하여 데이터를 추가했으나, 현재는 지원하고 있지 않습니다.
ignore_index=True 옵션을 추가해야 에러가 발생하지 않습니다.
dic ={
'name' : '김사과',
'group' : '과수원',
'company' : 'apple',
'gender' : '여자',
'birthday' : '2000-01-01',
'height' : 160,
'blood' : 'A',
'brand' : 1234567
}
# 행 추가
# concat(): 데이터를 합침, axis=0(기본값)
df = pd.concat([df, pd.DataFrame(dic, index=[0])], ignore_index=True)
df
# 열 추가
df['nation'] = '대한민국'
df.head()
문제
'김사과'님의 국적을 '미국'으로 변경
단, loc를 사용
# 뒤에 column의 Value값에 다른 값 저장
df.loc[df['name']=='김사과', 'nation']='미국'
df
# 행 제거
df.drop(20, axis=0)
df.tail(2)
df.drop([1,3,5,20], axis=0)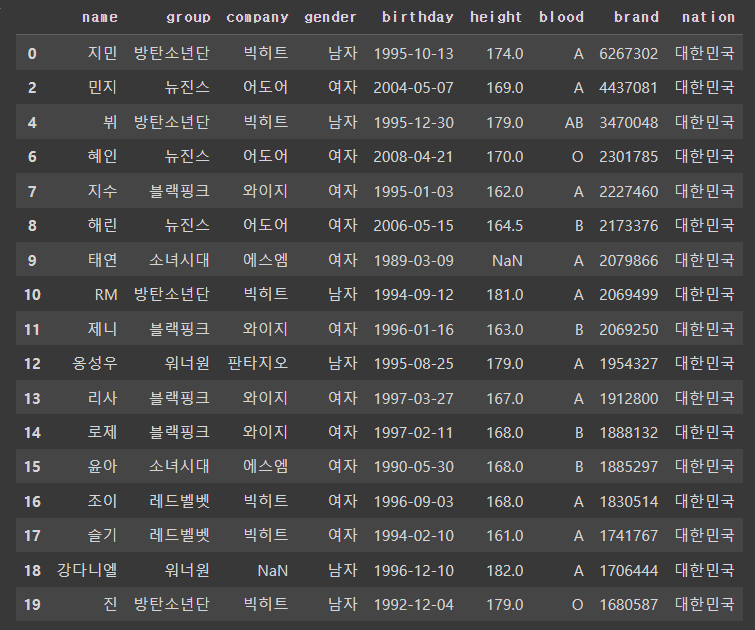
# 열 제거
df.drop('nation',axis=1)
df.drop(['group', 'nation'],axis=1)