Python/머신러닝(ML)
Python(18)- Iris Dataset
두설날
2024. 6. 11. 09:09

*이 글을 읽기전에 작성자 개인의견이 있으니, 다른 블로그와 교차로 읽는것을 권장합니다.*
1. Iris DataSet
데이터셋: 특정한 작업을 위해 데이터를 관련성 있게 모아놓은 것
https://scikit-learn.org/stable/api/sklearn.datasets.html#module-sklearn.datasets
sklearn.datasets
Utilities to load popular datasets and artificial data generators. User guide. See the Dataset loading utilities section for further details. Loaders: Sample generators:
scikit-learn.org
from sklearn.datasets import load_irisiris = load_iris()
iris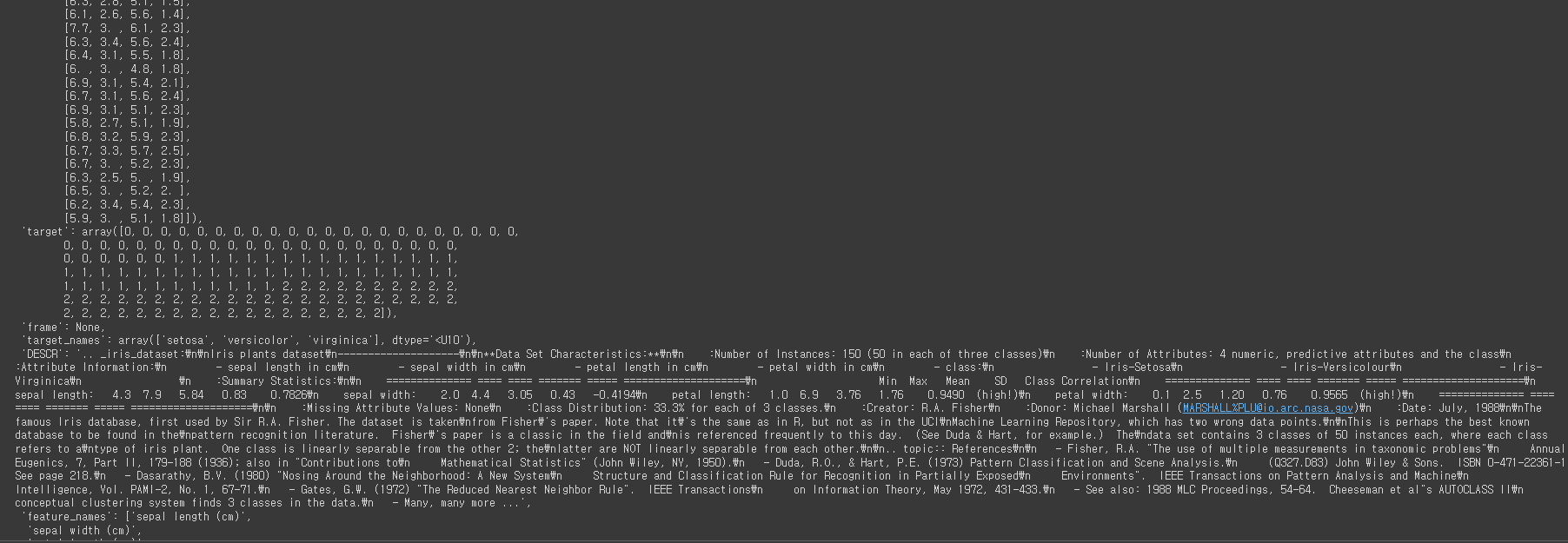
print(iris['DESCR'])
sepal length in cm : 꽃받침의 길이
sepal width in cm : 꽃받침의 너비
petal length in cm : 꽃받침의 길이
petal width in cm : 꽃잎의 너비
data = iris['data']
data
feature_names = iris['feature_names']
feature_names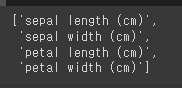
import pandas as pddf_iris = pd.DataFrame(data, columns=feature_names)
df_iris
target = iris['target']
target
target.shape
# target:2만 검증하려고 함
df_iris['target'] = target
df_iris
from sklearn.model_selection import train_test_split# train_test_split(독립변수, 종속변수, 테스트사이즈, 시드값 ...)
X_train, X_test, y_train, y_test = train_test_split(
df_iris.drop('target', axis=1), # 독립변수
df_iris['target'], # 종속변수
test_size=0.2, # 테스트 데이터 비율
random_state=2023 # 시드 값
)X_train.shape, X_test.shape
y_train.shape, y_test.shape
X_train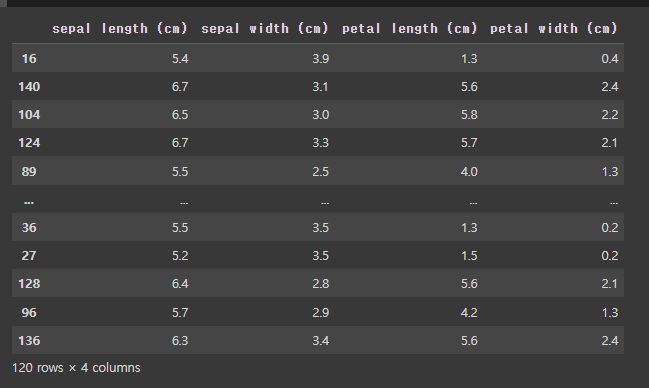
y_train
# LinearSVC(2차원) VS SVC(곡선, ) 모델사용차이는 복잡함차이
from sklearn.svm import SVC
from sklearn.metrics import accuracy_scoresvc = SVC()
svc.fit(X_train, y_train)
y_pred = svc.predict(X_test)
y_pred
print('정답율', accuracy_score(y_test, y_pred))
# 6.2 2.1 4.1 1.5
y_pred = svc.predict([[6.2, 2.1, 4.1, 1.5]])
y_pred