Python/머신러닝(ML)
K-최근접 이웃 알고리즘(KNN)
두설날
2024. 6. 20. 14:53

*이 글을 읽기전에 작성자 개인의견이 있으니, 다른 블로그와 교차로 읽는것을 권장합니다.*
KNN 알고리즘의 특성
- 비모수적 방법: KNN은 명시적인 학습 단계 없이 데이터를 분류하거나 예측합니다. 모델은 훈련 데이터의 분포에 직접 의존합니다.
- 메모리 기반: 모든 훈련 데이터를 메모리에 저장하고, 예측할 때마다 훈련 데이터와의 거리를 계산합니다.
- 거리 기반: 새로운 데이터 포인트를 예측할 때, 가장 가까운 K개의 이웃을 기준으로 예측합니다. 일반적으로 유클리드 거리, 맨해튼 거리 등을 사용합니다.
- 단순성: 이해하고 구현하기 쉬운 알고리즘입니다.
- 높은 계산 비용: 대규모 데이터셋에서는 예측 시점에서 많은 계산이 필요하므로 느릴 수 있습니다.
비모수 데이터의 성질
- 사전 가정 없음: 데이터의 분포에 대해 명시적인 가정을 하지 않습니다.
- 데이터 중심: 모델은 데이터 자체에 직접적으로 의존합니다.
- 고차원 데이터에 적합: 특성이 많은 고차원 데이터에서도 잘 작동할 수 있습니다.
KNN에 적합한 문제 유형
- 분류 문제: 이진 또는 다중 클래스 분류 문제에서 자주 사용됩니다.
- 회귀 문제: 연속적인 값을 예측할 때도 사용할 수 있습니다.
- 비선형 데이터: 데이터가 비선형적인 경우에도 효과적으로 사용할 수 있습니다.
KNN에서 K는 최근접점을 말함. 기준을 잡은 지점을 기준으로 몇개까지 k개의 지점을 찍어낼것인지에 대한 갯수를 말함. k의 갯수를 설정할 때 보통 홀수를 사용, 짝수는 2:2상황이 벌어질 수 있기에 답이 안나오는 상황발생 가능->따라서 홀수로 설정
k-neighbors classifer는 기본적으로 회귀, 분류모델을 이용해서 prediction(예측값)을 뽑아내어 분류하는 알고리즘 수학적(이론적)으로 피타고라스 정리공식(벡터값)을 사용: d^2=a^2+b^2
fishmarket 데이터셋으로 KNN알고리즘 : https://www.kaggle.com/datasets/vipullrathod/fish-market
Fish Market
Estimate the weight of a fish based on its species and the physical measurements
www.kaggle.com
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report, roc_auc_score
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score
from sklearn.metrics import accuracy_scorefish_df= pd.read_csv('/content/drive/MyDrive/KDT/6. 머신러닝과 딥러닝/Data/Fish.csv')
fish_df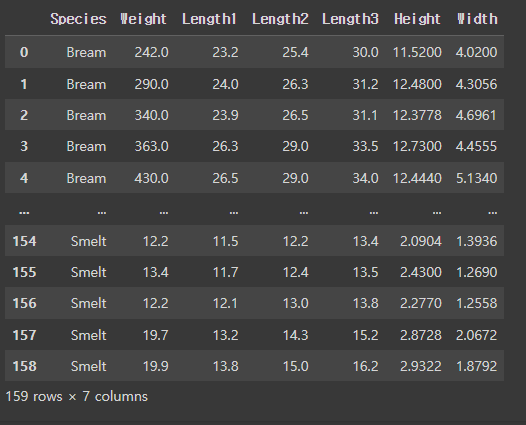
column 설명
- Species : 물고기 종
- Weight : 물고기 무게
- Length1 : 물고기 몸 길이(비늘~꼬리)
- Length2 : 물고기 표준 길이(머리~꼬리)
- Length3 : 물고기 전체 길이(머리~꼬리끝)
- Height : 물고기 높이(배의 높이)
- Width : 물고기 두께(배의 폭)
데이터 전처리
fish_df.info()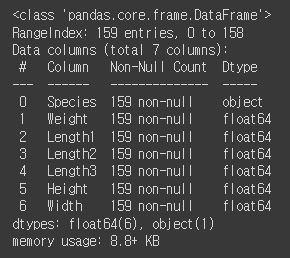
fish_df.describe()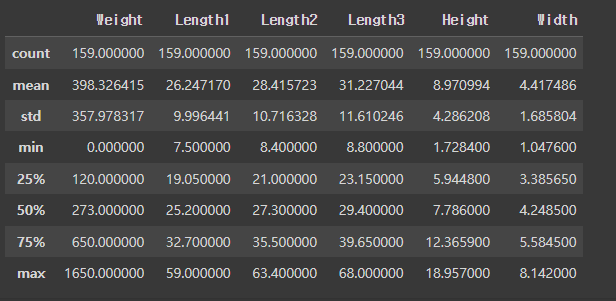
fish_df.isna().sum()
(fish_df['Weight'] == 0).sum()
fish_df = fish_df[fish_df['Weight'] !=0]
fish_df.describe()
fish_df['Species'].value_counts()
sns.displot(fish_df['Species'])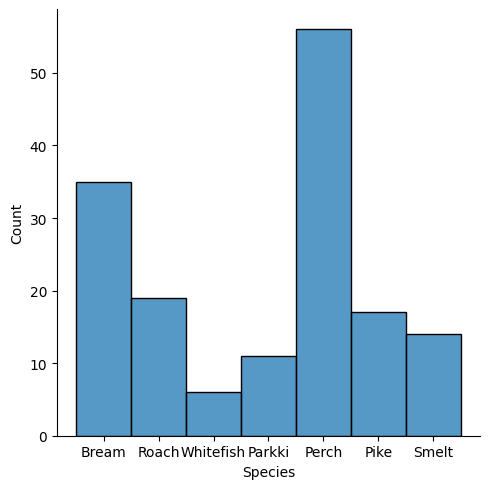
농어(Perch), 도미(Bream) 예측 분류
bream_weight = list(fish_df.loc[fish_df['Species'] == 'Bream']['Weight'])
bream_length = list(fish_df.loc[fish_df['Species'] == 'Bream']['Length1'])
perch_weight = list(fish_df.loc[fish_df['Species'] == 'Perch']['Weight'])
perch_length = list(fish_df.loc[fish_df['Species'] == 'Perch']['Length1'])
bream_weight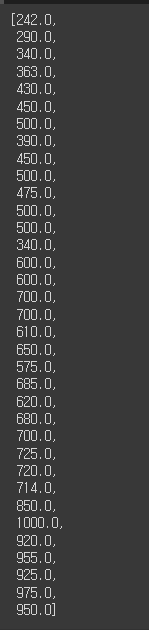
import matplotlib.pyplot as plt
plt.scatter(bream_length, bream_weight, label='Bream')
plt.scatter(perch_length, perch_weight, label='Perch')
plt.xlabel('length')
plt.ylabel('weigth')
plt.legend()
plt.show()
fish_length = bream_length + perch_length
fish_weight = bream_weight + perch_weight
fish_data = np.column_stack((fish_length, fish_weight))
fish_target = np.concatenate((np.ones(len(bream_weight)), np.zeros(len(perch_weight))))
train_input, test_input, train_target, test_target = train_test_split(fish_data, fish_target, stratify=fish_target)train_input.shape, train_target.shape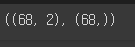
test_input.shape, test_target.shape
# 데이터 표준화
mean = np.mean(train_input, axis=0)
std = np.std(train_input, axis=0)
train_scaled = (train_input - mean) / std# 표준점수 2이상 이상치 제거
outline = []
for i, sample in enumerate(train_scaled):
for n in sample:
if abs(n) >= 2:
outline.append(i)
break
print(train_scaled[outline])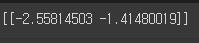
train_input = np.delete(train_input, outline, axis=0)
train_target = np.delete(train_target, outline, axis=0)
# KNN알고리즘 사용
kn = KNeighborsClassifier()
kn.fit(train_input, train_target)
kn.score(test_input, test_target)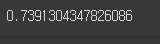
# 길이: 30, 무게: 600 분류
plt.scatter(bream_length, bream_weight, label='Bream')
plt.scatter(perch_length, perch_weight, label='Perch')
plt.scatter(30, 600, marker='^', color='red', label='New Data')
plt.xlabel('length')
plt.ylabel('weigth')
plt.legend()
plt.show()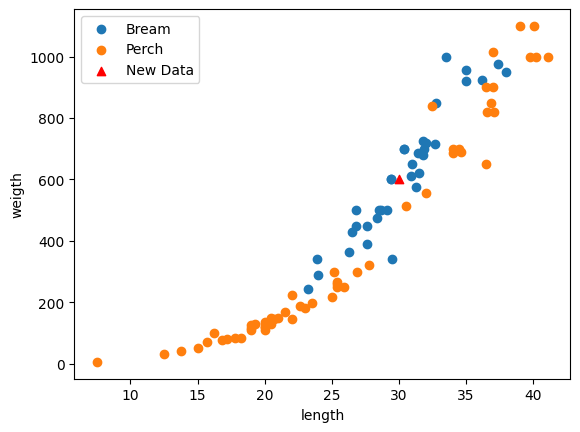
predict = kn.predict([[30, 600]])
print(predict)