Python/자연어처리
Python(44)- CNN 분류
두설날
2024. 7. 2. 17:01

*이 글을 읽기전에 작성자 개인의견이 있으니, 다른 블로그와 교차로 읽는것을 권장합니다.*
데이터 전처리 과정 : 이전 cbow 분류 전처리와 동일
더보기






















import urllib.request
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F # 파이토치 functional 추가
from copy import deepcopy
from torch.utils.data import Dataset, DataLoader
from tqdm.auto import tqdm# 깃허브에 올라온 파일을 가져오기 위해선, filename = ''설정해줘야 함.
urllib.request.urlretrieve('https://raw.githubusercontent.com/e9t/nsmc/master/ratings_train.txt', filename='ratings_train.txt' )
urllib.request.urlretrieve('https://raw.githubusercontent.com/e9t/nsmc/master/ratings_test.txt', filename='ratings_test.txt' )train_dataset = pd.read_table('ratings_train.txt')
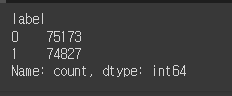
train_dataset# pos, neg 비율
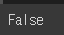
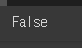
train_dataset['label'].value_counts()sum(train_dataset['document'].isnull())train_dataset['document'].isnull()train_dataset = train_dataset[~train_dataset['document'].isnull()]
sum(train_dataset['document'].isnull())train_datasetTokenization
- 자연어를 모델이 이해하기 위해서는 자연어를 숫자의 형식으로 변형시켜야함
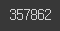
train_dataset['document'].iloc[0].split()vocab = set()
for doc in train_dataset['document']:
for token in doc.split():
vocab.add(token)
len(vocab)# 단어의 빈도수 구하기
'''
[('아', 1204),
('더빙', 2),
('진짜',5929),
('짜증나네요',10),
('목소리',99),
]
'''
vocab_cnt_dict = {}
for doc in train_dataset['document']:
for token in doc.split():
if token not in vocab_cnt_dict:
vocab_cnt_dict[token] = 0
vocab_cnt_dict[token] += 1vocab_cnt_list = [(token, cnt) for token, cnt in vocab_cnt_dict.items()]
vocab_cnt_list[:10]top_vocabs = sorted(vocab_cnt_list, key=lambda tup:tup[1], reverse=True)
top_vocabs[:10]cnts = [cnt for _, cnt in top_vocabs]
np.mean(cnts)cnts[:10]sum(np.array(cnts) > 2)n_vocab = sum(np.array(cnts) > 2)
top_vocabs_truncated = top_vocabs[:n_vocab]
top_vocabs_truncated[:5]vocabs = [token for token, _ in top_vocabs_truncated]
vocabs[:5]special token
[UNK] : Unknown Token
[PAD] : Padding Token
unk_token = '[UNK]'
unk_token in vocabspad_token = '[PAD]'
pad_token in vocabsvocabs.insert(0, unk_token)
vocabs.insert(0, pad_token)
vocabs[:5]idx_to_token = vocabs
token_to_idx = {token: i for i, token in enumerate(idx_to_token)}class Tokenizer:
def __init__(self, vocabs, use_padding=True, max_padding=64, pad_token='[PAD]', unk_token='[UNK]'):
self.idx_to_token = vocabs
self.token_to_idx = {token: i for i, token in enumerate(self.idx_to_token)}
self.use_padding = use_padding
self.max_padding = max_padding
self.pad_token = pad_token
self.unk_token = unk_token
self.unk_token_idx = self.token_to_idx[self.unk_token]
self.pad_token_idx = self.token_to_idx[self.pad_token]
def __call__(self, x:str):
token_ids = []
token_list = x.split()
for token in token_list:
if token in self.token_to_idx:
token_idx = self.token_to_idx[token]
else:
token_idx = self.unk_token_idx
token_ids.append(token_idx)
if self.use_padding:
token_ids = token_ids[:self.max_padding]
n_pads = self.max_padding - len(token_ids)
token_ids = token_ids + [self.pad_token_idx] * n_pads
return token_idstokenizer = Tokenizer(vocabs, use_padding=False)
sample = train_dataset['document'].iloc[0]
print(sample)tokenizer(sample) # [51, 1, 5, 10485, 1064]token_length_list = []
for sample in train_dataset['document']:
token_length_list.append(len(tokenizer(sample)))
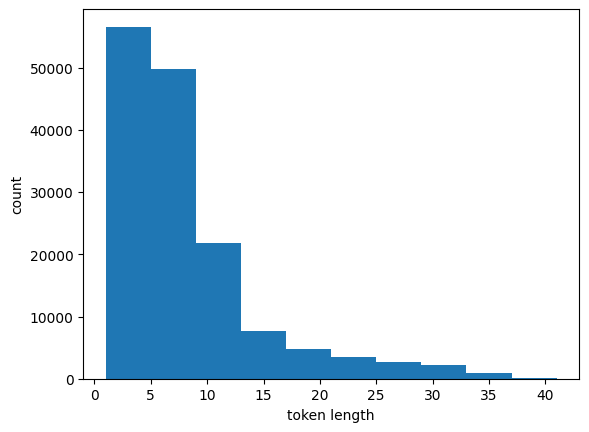
plt.hist(token_length_list)
plt.xlabel('token length')
plt.ylabel('count')max(token_length_list)tokenizer = Tokenizer(vocabs, use_padding=True, max_padding=50)
print(tokenizer(sample)) # 데이터로더, 배치사이즈, 데이터셋 필요train_valid_dataset = pd.read_table('ratings_train.txt')
test_dataset = pd.read_table('ratings_test.txt')
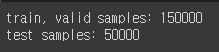
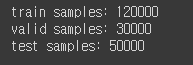
print(f'train, valid samples: {len(train_valid_dataset)}')
print(f'test samples: {len(test_dataset)}')train_valid_dataset.head()train_valid_dataset = train_valid_dataset.sample(frac=1.)
train_valid_dataset.head()train_ratio = 0.8
n_train = int(len(train_valid_dataset) * train_ratio)
train_df = train_valid_dataset[:n_train]
valid_df = train_valid_dataset[n_train:]
test_df = test_dataset
print(f'train samples: {len(train_df)}')
print(f'valid samples: {len(valid_df)}')
print(f'test samples: {len(test_df)}')# 1/10으로 샘플링
train_df = train_df.sample(frac=0.8)
valid_df = valid_df.sample(frac=0.8)
test_df = test_df.sample(frac=0.8)
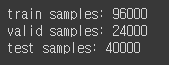
print(f'train samples: {len(train_df)}')
print(f'valid samples: {len(valid_df)}')
print(f'test samples: {len(test_df)}')class NSMCDataset(Dataset):
def __init__(self, data_df, tokenizer=None):
self.data_df = data_df
self.tokenizer = tokenizer
def __len__(self):
return len(self.data_df)
def __getitem__(self, idx):
sample_raw = self.data_df.iloc[idx]
sample = {}
sample['doc'] = str(sample_raw['document'])
sample['label'] = int(sample_raw['label'])
if self.tokenizer is not None:
sample['doc_ids'] = self.tokenizer(sample['doc'])
return sampletrain_dataset = NSMCDataset(data_df=train_df, tokenizer=tokenizer)
valid_dataset = NSMCDataset(data_df=valid_df, tokenizer=tokenizer)
test_dataset = NSMCDataset(data_df=test_df, tokenizer=tokenizer)
print(train_dataset[0])def collate_fn(batch):
keys = [key for key in batch[0].keys()]
data = {key: [] for key in keys}
for item in batch:
for key in keys:
data[key].append(item[key])
return datatrain_dataloader = DataLoader(
train_dataset,
batch_size=128,
collate_fn=collate_fn, # 배치사이즈를 어떻게 묶을것인가
shuffle=True
)
valid_dataloader = DataLoader(
valid_dataset,
batch_size=128,
collate_fn=collate_fn,
shuffle=False
)
test_dataloader = DataLoader(
test_dataset,
batch_size=128,
collate_fn=collate_fn,
shuffle=False
)sample = next(iter(test_dataloader))
sample.keys() # dict_keys(['doc', 'label', 'doc_ids'])sample['doc'][3] # 정말 재미지게 오랫동안 보게되는 드라마print(sample['doc_ids'][3]) # [4, 17366, 2223, 2798, 52, 0, ... 0]CNN Model
- https://young0378.tistory.com/142
- 위키독스 3-3 참조
Python(34)- CNN 모델링
*이 글을 읽기전에 작성자 개인의견이 있으니, 다른 블로그와 교차로 읽는것을 권장합니다.*1. CNN(Convolutional Neural Networks)합성곱 인공 신경망전통적인 뉴럴 네트워크에 컨볼루셔널 레이어를
young0378.tistory.com
convolution 연산방법
- convolution 출력텐서 공식
- 입력 데이터 : N X N
- 필터 크기(kernel_size) : F X F
- stride가 1일 때 : (N - F + 1) x (N - F + 1)
- stride : 입력데이터 이동 간격
- stride = S라 가정, 출력 데이터의 크기는 RoundDown(N - F / S) + 1
convolution 연산 종류
- 패딩
- 2D 컨볼루션
- 풀링
- 스트라이드 조절
- 드롭아웃 레이어
- FC 레이어
N-gram 언어모델
- 여러 카운트에 기반한 통계적 기계번역(SLM)의 일종
- 등장한 모든 단어를 고려한 것이 아닌, 일부 단어만을 파라미터로 접근하는 방법 상용
- n-gram의 n은 사용한 단어의 파라미터 갯수
- SLM의 학습 코퍼스(텍스트 데이터 집합)의 확률 0 가능성 문제점 해결 솔루션 목적 -> 학습 코퍼스 등장 확률 올리기
N-gram : n개의 연속적인 단어 나열
- 갖고있는 n개의 단어 단위를 토큰으로 간주
- unigram : 1개, ex) an
- bigrams : 2개, ex) adorable little
- trigrams : 3개, ex) an adorable little
- 4-grams : 4개, ex) an adorable little boy
- n-gram을 통한 언어 모델에서는 다음에 나올 단어의 예측은 오직 n-1개의 단어에만 의존
- ex)

N-gram 모델의 한계 : n-gram은 앞의 단어 몇 개만 보다 보니 의도하고 싶은 대로 문장을 끝맺음하지 못하는 경우, 전체 문장을 고려한 언어 모델보다는 정확도가 떨어지는 문제
- 1) 희소 문제 : n-gram에 대한 희소 문제가 존재
- 2) n개를 선택하는 trade-off 문제 :
- n을 크게 선택하면 실제 훈련 코퍼스에서 해당 n-gram을 카운트할 수 있는 확률은 적어지므로 희소 문제는 점점 심각
- n이 커질수록 모델 사이즈가 커진다는 문제점
- n을 작게 선택하면 훈련 코퍼스에서 카운트는 잘 되겠지만 근사의 정확도는 현실의 확률분포와 멀어지는 문제
- n은 최대 5를 넘게 잡아서는 안 된다고 권장
-위의 문제들을 해결하기 위해 인공신경망 언어모델 사용-
# 오차함수는 Relu사용
class SentenceCNN(nn.Module):
def __init__(self, vocab_size, embed_dim, word_win_size=[3, 5, 7]): # word win size는 CNN(딥러닝)에서는 filter역할이지만 자연어처리에서는 n-gram모델, 합성곱 정방행렬 3X3, 5X5, 7X7을 리스트로 표현
super().__init__()
self.vocab_size = vocab_size
self.embed_dim = embed_dim
self.word_win_size = word_win_size # 속성 저장
self.conv_list = nn.ModuleList(
[nn.Conv2d(1, 1, kernel_size=(w, embed_dim)) for w in self.word_win_size]
)
self.embeddings = nn.Embedding(vocab_size, embed_dim, padding_idx=0)
self.output_dim = len(self.word_win_size)
def forward(self, X): # 순전파, 학습되는 방향(label방향)
batch_size, seq_len =X.size()
X = self.embeddings(X) # batch_size * seq_len * embed_dim
X = X.view(batch_size, 1, seq_len, self.embed_dim) # view메서드 : 차원 수정, batch_size * channel(1) * seq_len(H) * embed_dim(W)
C = [F.relu(conv(X)) for conv in self.conv_list] # 오차값, 오차함수로 Relu사용
C_hat = torch.stack([F.max_pool2d(
c, c.size()[2:]).squeeze() for c in C], dim=1) # 차원1개 축소,
return C_hatclass Classifier(nn.Module):
def __init__(self, sr_model, output_dim, vocab_size, embed_dim, **kwargs):
super().__init__()
self.sr_model = sr_model(vocab_size=vocab_size, embed_dim=embed_dim, **kwargs)
self.input_dim = self.sr_model.output_dim
self.output_dim = output_dim
self.fc = nn.Linear(self.input_dim, self.output_dim)
def forward(self, x):
return self.fc(self.sr_model(x))model = Classifier(sr_model=SentenceCNN, output_dim=2, vocab_size=len(vocabs), embed_dim=16)
model.sr_model.embeddings.weight[0]
use_cuda = True and torch.cuda.is_available()
if use_cuda:
model.cuda()optimizer = optim.Adam(params=model.parameters(), lr=0.01)
calc_loss = nn.CrossEntropyLoss()n_epoch = 10
global_i = 0
valid_loss_history = []
train_loss_history = []
best_model = None
best_epoch_i = None
min_valid_loss = 9e+9
for epoch_i in range(n_epoch):
model.train()
for batch in train_dataloader:
optimizer.zero_grad()
X = torch.tensor(batch['doc_ids'])
y = torch.tensor(batch['label'])
if use_cuda:
X = X.cuda()
y = y.cuda()
y_pred = model(X)
loss = calc_loss(y_pred, y)
if global_i % 1000 == 0:
print(f'i: {global_i}, epoch: {epoch_i}, loss: {loss.item()}')
train_loss_history.append((global_i, loss.item()))
loss.backward()
optimizer.step()
global_i += 1
model.eval()
valid_loss_list = []
for batch in valid_dataloader:
X = torch.tensor(batch['doc_ids'])
y = torch.tensor(batch['label'])
if use_cuda:
X = X.cuda()
y = y.cuda()
y_pred = model(X)
loss = calc_loss(y_pred, y)
valid_loss_list.append(loss.item())
valid_loss_mean = np.mean(valid_loss_list)
valid_loss_history.append((global_i, valid_loss_mean.item()))
if valid_loss_mean < min_valid_loss:
min_valid_loss = valid_loss_mean
best_epoch_i = epoch_i
best_model = deepcopy(model)
if epoch_i % 2 == 0:
print("*"*30)
print(f'valid_loss_mean: {valid_loss_mean}')
print("*"*30)
print(f'best_epoch: {best_epoch_i}')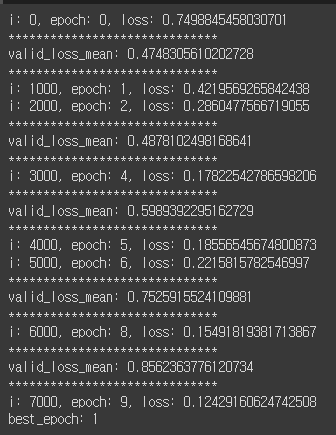
def calc_moving_average(arr, win_size=100):
new_arr = []
win = []
for i, val in enumerate(arr):
win.append(val)
if len(win) > win_size:
win.pop(0)
new_arr.append(np.mean(win))
return np.array(new_arr)valid_loss_history = np.array(valid_loss_history)
train_loss_history = np.array(train_loss_history)
plt.figure(figsize=(12,8))
plt.plot(train_loss_history[:,0],
calc_moving_average(train_loss_history[:,1]), color='blue')
plt.plot(valid_loss_history[:,0],
valid_loss_history[:,1], color='red')
plt.xlabel("step")
plt.ylabel("loss")
Evaluation
model = best_model
model.eval()
total = 0
correct = 0
for batch in tqdm(test_dataloader,
total=len(test_dataloader.dataset)//test_dataloader.batch_size):
X = torch.tensor(batch['doc_ids'])
y = torch.tensor(batch['label'])
if use_cuda:
X = X.cuda()
y = y.cuda()
y_pred = model(X)
curr_correct = y_pred.argmax(dim=1) == y
total += len(curr_correct)
correct += sum(curr_correct)
print(f'test accuracy: {correct/total}')
자연어처리를 하기위해 RNN으로 시작했으나, vanil.RNN의 성능은 저조하기에 CNN으로 자연어처리