Python(57)- YOLO

*이 글을 읽기전에 작성자 개인의견이 있으니, 다른 블로그와 교차로 읽는것을 권장합니다.*
1. YOLO
- 이미지 분류(Classification), 객체 탐지(Detection), 인스턴스 분할(Segmentation) 작업에 사용할 수 있는 모델
- YOLO는 2015년, Joseph Redmond가 처음 출시한 이후 컴퓨터 비전 커뮤니티에 의해 성장
- 초기버전(1~4)에서의 YOLO는 Redmond가 작성한 커스텀 딥러닝 프레임워크인 Darknet에서 유지
- YOLOv3 레포를 PyTorch로 작성하여 Ultralytics에서 YOLOv5를 출시
- 유연한 Python 구조 덕분에 YOLOv5는 SOTA 레포가 되었음
- Ultralytics는 2023년 1월에 YOLOv8을 출시
- 아키텍처 요약
- Object Detection 문제를 regression 문제로 정의하는 것을 통해 bounding box 좌표 및 각 클래스일 확률을 계산
1-1. YOLO의 장점
- Sliding Window 방식이 아닌 CNN을 사용하여 이미지 전역의 Contextual Information을 얻어 학습 성능을 높임
- 일반적인 Object의 표현을 학습하기에 Domain이 달라도 높은 성능을 보임
1-2. YOLOv8
- Backbone, Neck Head로 구성
- Backbone: 전체 네트워크의 본체 파트
- Neck: Backbone과 Head를 연결
- Head: 최종 출력 생성 파트
- 이전 버전에 비해서 더 복잡한 구조를 가지고 있어 높은 정확도를 보여줄 뿐 아니라, 빠른 속도를 보임
2. PascalVOC 데이터
2-1. PascalVOC 2007
- 분류와 객체 검출을 위해 만들어진 데이터셋
- 총 20개의 클래스를 가지고 있음
- Person: person
- Animal: bird, cat, cow, dog, horse, sheep
- Vehicle: aeroplane, bicycle, boat, bus, car, motorbike, train
- Indoor: bottle, chair, dining table, potted plant, sofa, tv/monitor
2-2. 실습 준비
- 학습 데이터
- train: 2501장
- val: 2510장
- 학습 데이터가 너무 적어서 train과 val을 합쳐서 학습시킨 후, 테스트 데이터를 검증 데이터셋으로 사용
- 테스트 데이터
- test: 4952장
!wget http://pjreddie.com/media/files/VOCtrainval_06-Nov-2007.tar
!wget http://pjreddie.com/media/files/VOCtest_06-Nov-2007.tar
pascal_datasets
pascal_datasets/trainval
pascal_datasets/test
pascal_datasets/VOC
pascal_datasets/VOC/images
pascal_datasets/VOC/labels
pascal_datasets/VOC/images/train2007
pascal_datasets/VOC/images/val2007
pascal_datasets/VOC/images/test2007
pascal_datasets/VOC/labels/train2007
pascal_datasets/VOC/labels/val2007
pascal_datasets/VOC/labels/test2007from pathlib import Path
root = Path('./pascal_datasets')
Path('./pascal_datasets/trainval').mkdir(parents=True, exist_ok =True)
Path('./pascal_datasets/test').mkdir(parents=True, exist_ok =True)
# exist_ok는 존재해도 디렉토리 만들어지게 옵션, parents는 상위 폴더 없을 경우 생성 옵션
for path1 in ('images', 'labels'):
for path2 in ('train2007', 'val2007', 'test2007'):
new_path = root / 'VOC' / path1 / path2
new_path.mkdir(parents=True, exist_ok=True)!tar -xvf VOCtrainval_06-Nov-2007.tar -C ./pascal_datasets/trainval/
!tar -xvf VOCtest_06-Nov-2007.tar -C ./pascal_datasets/test/
2-3. YOLO 포맷으로 변경
- xml에서 (xmin, ymin, xmax, ymax)을 YOLO 모델에서 사용하기 위해 포맷 변경이 필요
- YOLO 형식 -> (클래스번호, x의 center좌표, y의 center좌표, 너비, 높이)
!git clone https://github.com/ssaru/convert2Yolo.git%cd convert2Yolo
%pip install -r requirements.txt
2-4. names 파일
- 머신러닝, 딥러닝 모델이 데이터셋 내의 클래스를 인식하고 구분할 수 있도록 클래스 이름을 정의한 파일 형식
- YOLO와 같은 유명한 객체 탐지 알고리즘을 구현하는데 제공
# voc.names를 convert2Yolo안에 넣어주기
# voc.names 파일은 다운로드
# trainval 데이터 yolo 포맷 변환
!python3 example.py --datasets VOC --img_path /content/pascal_datasets/trainval/VOCdevkit/VOC2007/JPEGImages/ --label /content/pascal_datasets/trainval/VOCdevkit/VOC2007/Annotations/ --convert_output_path /content/pascal_datasets/VOC/labels/train2007/ --img_type ".jpg" --manifest_path /content/ --cls_list_file ./voc.names
# test 데이터 yolo 포멧 변환
!python3 example.py --datasets VOC --img_path /content/pascal_datasets/test/VOCdevkit/VOC2007/JPEGImages/ --label /content/pascal_datasets/test/VOCdevkit/VOC2007/Annotations/ --convert_output_path /content/pascal_datasets/VOC/labels/test2007/ --img_type ".jpg" --manifest_path /content/ --cls_list_file ./voc.names
2-5. PascalVOC 제공 파일로 train, val 라벨 분할
- /content/pascal_datasets/trainval/VOCdevkit/VOC2007/ImageSets/Main/val.txt 파일을 읽기
- /content/pascal_datasets/VOC/labels/train2007 파일 중 위 txt문서에 있는 파일을 /content/pascal_datasets/VOC/labels/val2007 로 옮기기
import shutil
import ospath = '/content/pascal_datasets/trainval/VOCdevkit/VOC2007/ImageSets/Main/val.txt'
with open(path) as f:
image_ids = f.read().strip().split()
for id in image_ids:
ori_path = '/content/pascal_datasets/VOC/labels/train2007'
mv_path = '/content/pascal_datasets/VOC/labels/val2007'
shutil.move(f'{ori_path}/{id}.txt', f'{mv_path}/{id}.txt')2-6. VOC/labels에 맞게 images 분할
/content/pascal_datasets/trainval/VOCdevkit/VOC2007/JPEGImages와 /content/pascal_datasets/test/VOCdevkit/VOC2007/JPEGImages에서 이미지를 가져와 디렉토리에 맞게 저장
path = '/content/pascal_datasets'
for folder, subset in ('trainval', 'train2007'), ('trainval', 'val2007'), ('test', 'test2007'):
ex_imgs_path = f'{path}/{folder}/VOCdevkit/VOC2007/JPEGImages'
label_path = f'{path}/VOC/labels/{subset}'
img_path = f'{path}/VOC/images/{subset}'
print(subset, ": ", len(os.listdir(label_path)))
for lbs_list in os.listdir(label_path):
shutil.move(os.path.join(ex_imgs_path, lbs_list.split('.')[0]+'.jpg'),
os.path.join(img_path, lbs_list.split('.')[0]+'.jpg'))
3. 커스텀 데이터 준비
1. CVAT https://www.cvat.ai/
2. 새로운 프로젝트 생성
3. 라벨 정보 입력(이름과 색상 설정)
4. 새로운 task 생성
5. 이미지 업로드
6. 이미지 데이터 경계상자 라벨링
7. 라벨링 결과물 저장
8. 결과물 YOLO 포맷으로 Export
9. Request에서 다운로드
CVAT
Powerfull and efficient open source data annotation platform for computer vision datasets
www.cvat.ai
객체 툴 따는 사이트에서 회원가입 후 new project와 new task 만들기



project는 이미지만 모으는 것이지만, task는 이미지 실제로 넣고, annotation 처리









4. YOLO 모델 불러오기
%cd /content/
# 6.2로 태그한 데이터를 브랜치로 받아오기 가능
!git clone -b v6.2 https://github.com/ultralytics/yolov5.git
%cd yolov5
%pip install -qr requirements.txt
!pip install numpy==1.23.0
import torch
import utils
# 노트북 초기화 함수 호출 및 결과를 저장
display = utils.notebook_init()
5. WanDB를 이용한 학습 및 평가 과정 로깅
- WanDB https://wandb.ai/site
- 머신러닝/딥러닝 개발자를 위한 종합적인 보조 도구
- 딥러닝 모델 학습할 때 학습 과정에 대해 로깅을 진행
- 손실값의 감소하는 형태를 쉽게 파학할 수 있음
- 팀 단위로 실험 결과를 추적할 수 있도록 해주기 때문에, 웹에서 편리하게 분석이 가능
Weights & Biases: The AI Developer Platform
The Weights & Biases MLOps platform helps AI developers streamline their ML workflow from end-to-end.
wandb.ai
wandb 설치
%pip install wandb
import wandbwandb api key 입력
wandb.login()
6. 실험의 재현성 보장
import random
import numpy as npseed = 2024
deterministic = True
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
if deterministic:
# CuDNN을 사용하는 GPU 연산에서 설정: True(동일한 입력에 대해 항상 동일한 결과를 보장)
torch.backends.cudnn.deterministic = True
# CuDNN 벤치마크 모드를 활성화
# 입력 크기가 변겨오디지 않을 경우, 최적의 알고리즘을 선택하여 성능을 향상
torch.backends.cudnn.benchmark = True7. data.yaml 파일
- custom_voc.yaml: Pascal voc 2007 데이터 명시 파일
- custom_dataset.yaml: 직접 라벨링한 테스트 데이터 명시 파일
- 파일 경로: /content/yolo5/data/
8. YOLOv5 가중치 파일
- yolov5s.pt : 가장 작은 버전으로 경량화된 모델이며 작은 크기의 객체를 감지하거나 시스템 리소스가 제한된 환경에서 사용
- yolov5m.pt : 중간 크기의 모델로 기본적인 객체 탐지와 분류에 적합
- yolov5l.pt : 큰 모델로 더 높은 정확도를 제공. 크기가 큰 객체나 복잡한 시나리오에 유용
- yolov5x.pt : 가장 큰 모델로 가장 높은 정확도를 목표로 함
%cd /content/yolov5
!python3 train.py --img 640 --batch 16 --epochs 10 --data custom_voc.yaml --weights yolov5s.pt --seed 2024
# /content/yolov5/runs/train/exp/weights/best.pt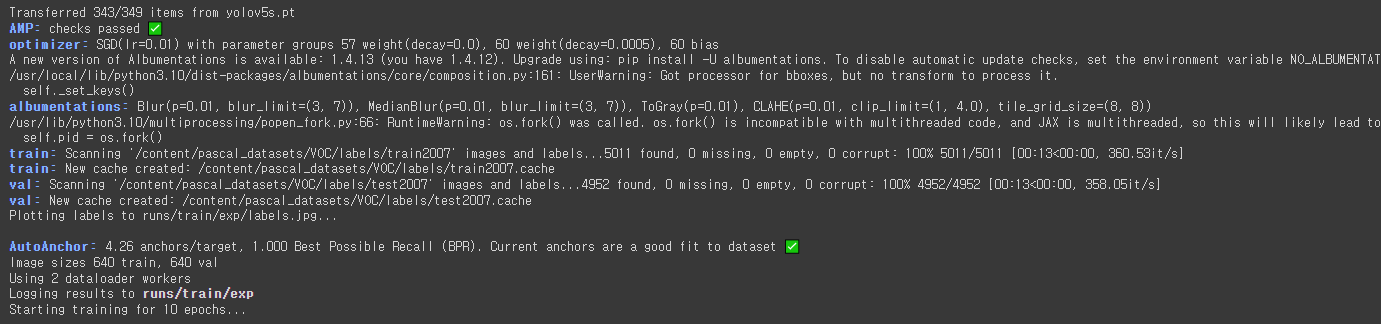



9. mAP(mean Average Precision)
- Precision(정밀도): 모델이 검출한 객체 중에서 실제로 객체인 비율
- True Positive(TP): 올바르게 검출한 객체
- False Positive(FP): 잘못 검출한 객체
- Recall(재현율): 실제 객체 중에서 모델이 올바르게 검출한 비율
- False Negative(FN): 검출하지 못한 객체
- Average Precision(AP)
- Precision과 Recall의 관계를 나타내는 Precision-Recall 곡선의 아래 면적(Area Under Curve)을 계산하여 얻음
- mean Average Precision(mAP)
- 다양한 객체 클래스에 대해 AP를 평균한 값
- 예) 클래스 1: AP = 0.75 클래스 2: AP = 0.85 클래스 3: AP = 0.8 mAP = 0.75+0.85+0.8 / 3 = 0.8
- 모델이 다양한 객체 클래스를 얼마나 잘 검출하고 있는지를 종합적으로 평가할 수 있는 중요한 지표
- 객체 검출 모델의 성능을 비교할 때 많이 사용 -> mAP 값이 높을수록 모델의 검출 성능이 좋다는 것을 의미
!python val.py --weights /content/yolov5/runs/train/exp/weights/best.pt --data custom_voc.yaml --img 640 --iou 0.5 --task test --half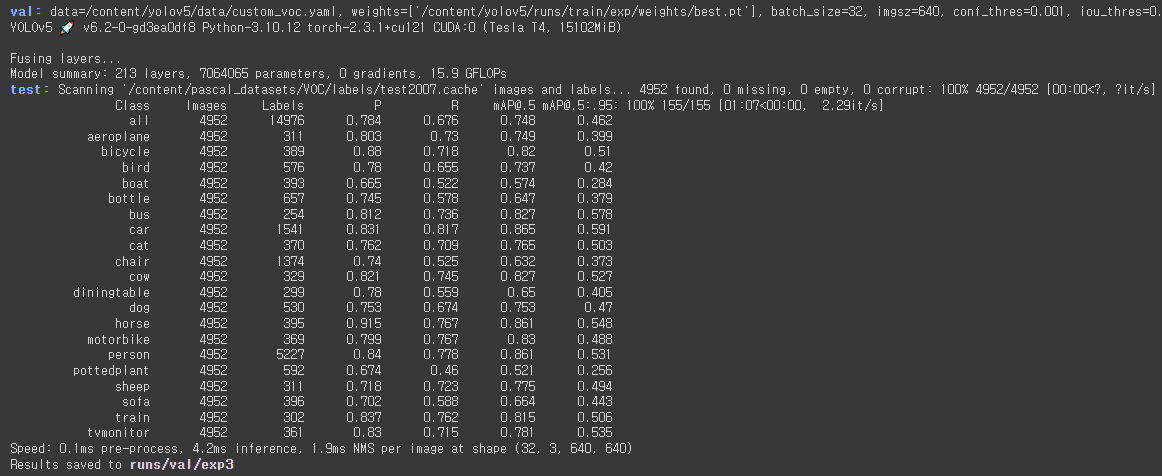
custom_images 폴더 이미지들
/content/pascal_datasets/VOC/
에 custom_datasets 폴더 만들고 그안에 또
obj_train_data 폴더 만들어서 그안에 넣어줌
!python val.py --weights /content/yolov5/runs/train/exp/weights/best.pt --data custom_dataset.yaml --img 640 --iou 0.5 --task test --half!python detect.py --weights /content/yolov5/runs/train/exp/weights/best.pt --img 640 --conf 0.25 --source /content/pascal_datasets/VOC/images/test2007!python detect.py --weights /content/yolov5/runs/train/exp/weights/best.pt --img 640 --conf 0.25 --source /content/pascal_datasets/VOC/custom_datasets/obj_train_data