Python/컴퓨터 비전
Python(58)- YOLO를 활용한 사진 분류기
두설날
2024. 8. 7. 14:37

*이 글을 읽기전에 작성자 개인의견이 있으니, 다른 블로그와 교차로 읽는것을 권장합니다.*
Kaggle에서 폐암 데이터시트를 가져오고, 데이터를 YOLO를 이용하여 분류하는 간단한 예제를 시작, 데이터 전처리와 후처리, 그리고 시각화와 yaml확장자 파일까지 만들어본다. 시작하기전에 캐글 데이터를 가져오기 위해서 kaggle로그인한 후, API를 가져와서 적용한다.
kaggle사이트는 다음과 같다.
https://www.kaggle.com/datasets/hamdallak/the-iqothnccd-lung-cancer-dataset/data
The IQ-OTH/NCCD lung cancer dataset
Lung Cancer CT Scans from Iraqi hospitals: Normal, Benign, and Malignant Cases
www.kaggle.com
데이터학습에 시간이 오래걸리기 때문에 GPU로 진행
import os
import random
import shutil
import cv2
import glob
import yaml # yaml파일 만들기
import ultralytics
import numpy as np
import torch
from torchvision import transforms
from tqdm import tqdm
from ultralytics import YOLO
#시각화 모듈
import matplotlib.pyplot as plt
from PIL import Imagerandom.seed(2024)!kaggle datasets download -d hamdallak/the-iqothnccd-lung-cancer-dataset
!unzip -q /content/the-iqothnccd-lung-cancer-dataset.zip# data폴더 만들고 수동으로 파일 옮기기
data_root = '/content/The IQ-OTHNCCD lung cancer dataset'
file_root = f'{data_root}/data'
project_name = 'lung_cancer'
# 정리할 디렉토리 정의
train_file_root = f'{data_root}/{project_name}'
train_root = f'{data_root}/{project_name}/train'
valid_root = f'{data_root}/{project_name}/valid'
test_root = f'{data_root}/{project_name}/test'오늘은 YOLO를 활용하여 Classification(객체 분류)의 목적으로 사용해본다.
# 3종류의 클래스 디렉토리를 data 안으로 넣어줌
# file_root에 있는 모든 디렉토리와 파일을 리스트로 만듦
cls_list = os.listdir(file_root)
cls_list
for folder in [train_root, valid_root, test_root]:
if not os.path.exists(folder):
os.makedirs(folder)
for cls in cls_list:
cls_folder = f'{folder}/{cls}'
if not os.path.exists(cls_folder):
os.makedirs(cls_folder)for cls in cls_list:
file_list = os.listdir(f'{file_root}/{cls}')
random.shuffle(file_list)
test_ratio = 0.1
num_file = len(file_list)
test_list = file_list[:int(num_file*test_ratio)]
valid_list = file_list[int(num_file*test_ratio):int(num_file*test_ratio)*2]
train_list = file_list[int(num_file*test_ratio)*2:]
# print(test_list)
# print(valid_list)
# print(train_list)
for i in test_list:
shutil.copyfile(f'{file_root}/{cls}/{i}', f'{test_root}/{cls}/{i}')
for i in valid_list:
shutil.copyfile(f'{file_root}/{cls}/{i}', f'{valid_root}/{cls}/{i}')
for i in train_list:
shutil.copyfile(f'{file_root}/{cls}/{i}', f'{train_root}/{cls}/{i}')test_file_list = glob.glob(f'{test_root}/*/*')
random.shuffle(test_file_list)
# test_file_list
plt.figure(figsize=(20, 10))
for i in range(10):
test_img_path = os.path.join(test_root, test_file_list[i])
ori_img = Image.open(test_img_path).convert('RGB')
plt.subplot(2, 5, (i+1))
plt.title(test_file_list[i].split('/')[-2])
plt.imshow(ori_img)
plt.show()
project_root = '/content/The IQ-OTHNCCD lung cancer dataset/lung_cancer'data = dict()
data['train'] = train_root
data['val'] = valid_root
data['test'] = test_root
data['nc'] = len(cls_list)
data['names'] = cls_list
with open(f'{project_root}/lung_cancer.yaml', 'w') as f:
yaml.dump(data, f)!pip install ultralyticsultralytics.checks()
%cd /content/The IQ-OTHNCCD lung cancer dataset/lung_cancer
YOLO모델 가져오기
model = YOLO('yolov8s-cls.pt')
results = model.train(data=f'{data_root}/{project_name}', epochs=50, batch=8, device=0, patience=30, name='lung_cancer_s')
result_folder = f'{project_root}/runs/classify/lung_cancer_s'model = YOLO(f'{result_folder}/weights/best.pt')
# modelmetrics = model.val(split='test')
metrics
Ultralytics YOLOv8.2.74 🚀 Python-3.10.12 torch-2.3.1+cu121 CUDA:0 (Tesla T4, 15102MiB)
YOLOv8s-cls summary (fused): 73 layers, 5,079,043 parameters, 0 gradients, 12.5 GFLOPs
train: /content/The IQ-OTHNCCD lung cancer dataset/lung_cancer/train... found 879 images in 3 classes ✅
val: None...
test: /content/The IQ-OTHNCCD lung cancer dataset/lung_cancer/test... found 109 images in 3 classes ✅
test: Scanning /content/The IQ-OTHNCCD lung cancer dataset/lung_cancer/test... 109 images, 0 corrupt: 100%|██████████| 109/109 [00:00<?, ?it/s]
/usr/lib/python3.10/multiprocessing/popen_fork.py:66: RuntimeWarning: os.fork() was called. os.fork() is incompatible with multithreaded code, and JAX is multithreaded, so this will likely lead to a deadlock.
self.pid = os.fork()
classes top1_acc top5_acc: 100%|██████████| 7/7 [00:02<00:00, 3.03it/s]
all 0.991 1
Speed: 0.1ms preprocess, 10.5ms inference, 0.0ms loss, 0.0ms postprocess per image
Results saved to runs/classify/val
ultralytics.utils.metrics.ClassifyMetrics object with attributes:
confusion_matrix: <ultralytics.utils.metrics.ConfusionMatrix object at 0x7c37bf7b68c0>
curves: []
curves_results: []
fitness: 0.9954128563404083
keys: ['metrics/accuracy_top1', 'metrics/accuracy_top5']
results_dict: {'metrics/accuracy_top1': 0.9908257126808167, 'metrics/accuracy_top5': 1.0, 'fitness': 0.9954128563404083}
save_dir: PosixPath('runs/classify/val')
speed: {'preprocess': 0.09116557759976168, 'inference': 10.451257775682922, 'loss': 0.0016514314424007311, 'postprocess': 0.0014042635576440653}
task: 'classify'
top1: 0.9908257126808167
top5: 1.0IMG_SIZE = (512, 512)
test_data_transform = transforms.Compose([
transforms.Resize(IMG_SIZE),
transforms.ToTensor()
])img = Image.open(test_file_list[0]).convert('RGB')
img_src = test_data_transform(img)
print(img_src.shape)
x_tensor = img_src.unsqueeze(0)
print(x_tensor.shape)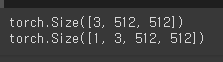
result = model(x_tensor)[0]
gt = test_file_list[0].split('/')[-2]
pt = model.names[torch.argmax(result.probs.data).item()]
print(gt)
print(pt)
plt.figure(figsize=(3,3))
plt.title(f'GT:{gt}, Predict:{pt}')
plt.imshow(np.array(img))
plt.show()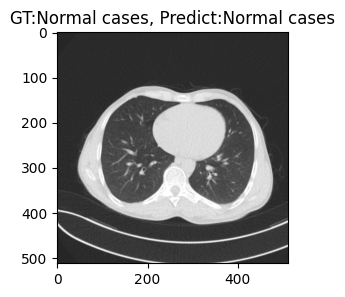
plt.figure(figsize=(20,5))
for idx in range(5):
img = Image.open(test_file_list[idx]).convert('RGB')
img_src = test_data_transform(img)
x_tensor = img_src.unsqueeze(0)
result = model.predict(x_tensor)[0]
gt = test_file_list[0].split('/')[-2]
pt = model.names[torch.argmax(result.probs.data).item()]
plt.subplot(1, 5, (idx+1))
plt.title(f'GT:{gt}, Predict:{pt}')
plt.imshow(img)
plt.show()
