
*이 글을 읽기전에 작성자 개인의견이 있으니, 다른 블로그와 교차로 읽는것을 권장합니다.*
데이터 불러와서 객체 설정
retail = pd.read_csv('/content/drive/MyDrive/KDT/5. 데이터 분석/데이터/OnlineRetail.csv')
retailretail.info()
# 행이 54만개, 열은 8개
위 데이터프레임의 컬럼 설명
- InvoiceNo : 주문 번호
StockCode : 상품 코드
Description : 상품 설명
Quantity : 주문 수량
InvoiceDate : 주문 날짜
UnitPrice : 상품 가격
CustomerID : 고객 아이디
Country : 고객 거주지역(국가)
# 각 컬럼당 null값이 몇 개 있는지 확인
# sum()으로 총합 알기
retail.isnull().sum()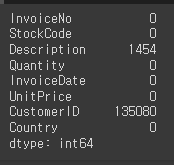
# 비회원/탈퇴/휴면회원 제거
# pd.notnull 은 null값 아닌것 판별
retail = retail[pd.notnull(retail['CustomerID'])] # 따라서 Null값이 아닐것만 뽑아서 저장# retail DataFrame의 row값
len(retail)
notnull값만 따로 뽑아 만든 데이터프레임으로, 행 54만개->40만개로 축소
# null값 없을 때, 수치 확인, min잘못된 값 확인
retail.describe()
# 구입 수량이 0 또는 0 이하인 데이터를 확인
retail[retail['Quantity'] <= 0]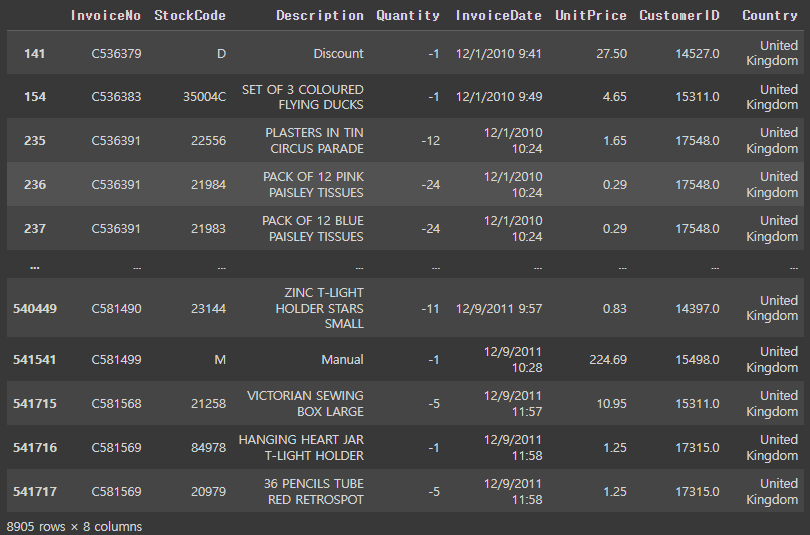
# 구입 수량이 1이상인 데이터만 저장
retail = retail[retail['Quantity']>=1# 확인
len(retail)
# 구입 가격이 0 또는 0 이하인 데이터를 확인
retail[retail['UnitPrice'] <=0]
# 구입 가격이 0 초과인 데이터만 저장
retail = retail[retail['UnitPrice'] >0]len(retail)
UnitPrice의 value값이 0인 행 제거
# 고객의 총 지출비용 파생변수 만들기
# 총 지출비용(CheckoutPrice) = 수량(Quantity) * 가격(UnitPrice)
retail['CheckoutPrice'] = retail['Quantity'] * retail['UnitPrice']
retail.head()
retail.info()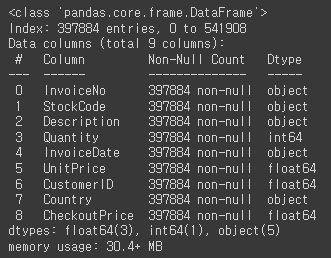
object type인 행의 value값들 숫자형으로 바꿀 필요 O
# object type -> datetime64 type으로 변경
retail['InvoiceDate'] = pd.to_datetime(retail['InvoiceDate'])retail.info()
# 전체 매출
total_revenue = retail['CheckoutPrice'].sum()
total_revenue
# 각 나라별 구매 횟수
# 그룹별 집계 작업이므로 groupby사용
retail.groupby('Country')['Quantity'].sum()
# pd.options.display.max_rows = 20
retail['Country'].value_counts()
# 국가별 매출
rev_by_countiries = retail.groupby('Country')['CheckoutPrice'].sum().sort_values()
rev_by_countiries
# 국가별 매출에 따른 막대그래프
plot = rev_by_countiries.plot(kind = 'bar', figsize=(12,6))
plot.set_xlabel('Country', fontsize=12)
plot.set_ylabel('Revenue', fontsize=12)
plot.set_title('Revenue By Country', fontsize=14)
plot.set_xticklabels(labels=rev_by_countiries.index, rotation=45)
rev_by_countiries / total_revenue
retail['InvoiceDate'].sort_values(ascending=False)
# 월별 매출 구하기
def extract_month(date):
month =str(date.month) # 12
if date.month < 10:
month='0'+month # 예) 2월일 경우 02
return str(date.year) + month # 201112.201101rev_by_month = retail.set_index('InvoiceDate').groupby(extract_month)['CheckoutPrice'].sum()
rev_by_month
xticlabels() : X축 눈금+라벨 생성
# 막대그래프 생성 함수
def plot_bar(df, xlabel, ylabel, title, titlesize=15, fontsize=12, rotation=45, figsize=(12, 6)):
plot = df.plot(kind='bar', figsize=figsize)
plot.set_xlabel(xlabel, fontsize=fontsize)
plot.set_ylabel(ylabel, fontsize=fontsize)
plot.set_title(title, fontsize=titlesize)
plot.set_xticklabels(labels=df.index, rotation=rotation)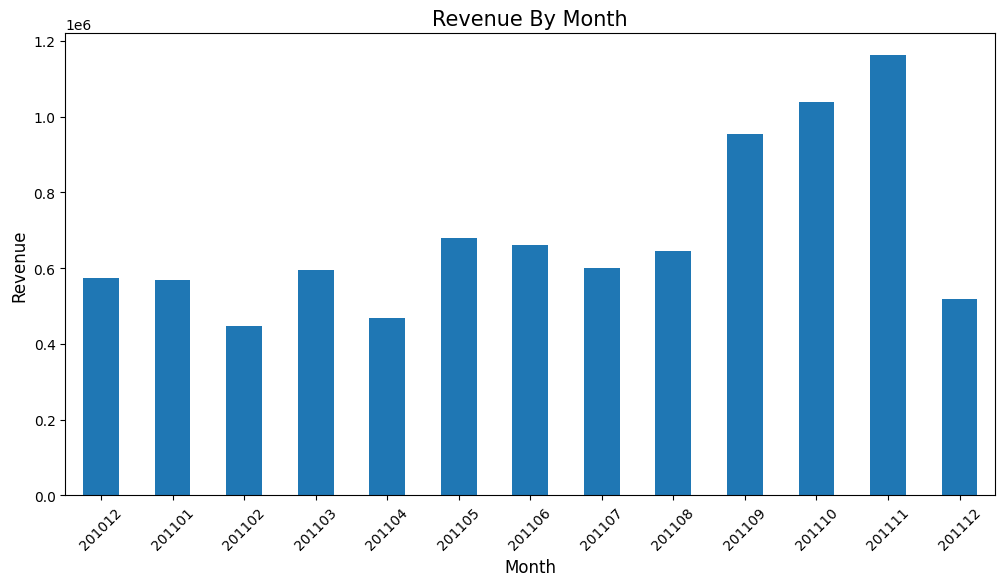
# 요일별 매출 구하기
def extract_dow(date):
return date.dayofweek# rev_by_dow = retail.set_index('InvoiceDate').groupby(extract_dow)['CheckoutPrice'].sum()
rev_by_dow = retail.set_index('InvoiceDate').groupby(lambda date: date.dayofweek)['CheckoutPrice'].sum()
rev_by_dow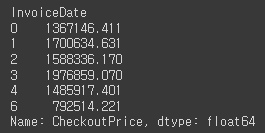
DAY_OF_WEEK = np.array(['Mon','Tue','Web','Thur','Fri','Sat','Sun'])
rev_by_dow.index = DAY_OF_WEEK[rev_by_dow.index]
rev_by_dow.index
rev_by_dow
plot_bar(rev_by_dow, 'DOW', 'Revenue', 'Revenue By DOW')
# 시간대별 매출 구하기
rev_by_hour = retail.set_index('InvoiceDate').groupby(lambda date: date.hour)['CheckoutPrice'].sum()
rev_by_hour
plot_bar(rev_by_hour, 'Hour', 'Revenue', 'Revenue By Hour')
데이터로부터 Insight(분석)
- 전체 매출의 약 82%가 UK에서 발생
- 매출은 꾸준히 성장하는 것으로 보임(11년 12월 데이터는 9일까지만 포함)
- 토요일은 영업을 하지 않음
- 새벽 6시에 오픈, 오후 8시에 마감이 예상
- 일주일 중 목요일까지는 성장세를 보이고 이후 하락
문제1
- 판매제품(StockCode) Top 10
- 단, 기준은 Quantity
- 해당 column에서 10개 슬라이싱
top_selling = retail.groupby('StockCode')['Quantity'].sum().sort_values(ascending=False)[:10]
top_selling
문제2
- 우수 고객(CustomerID) Top10
- 단, 기준은 CheckoutPrice
vvip = retail.groupby('CustomerID')['CheckoutPrice'].sum().sort_values(ascending=False).head(10)
# KeyError:10 실수 10이라서 에러
vvip
'Python > 데이터 분석(전처리, 시각화)' 카테고리의 다른 글
| 파이썬(10)-Boxplot, barplot으로 데이터분석 (0) | 2024.05.29 |
|---|---|
| 파이썬(9)-Seaborn, Folium을 이용한 산점도, marker 시각화 (0) | 2024.05.29 |
| 파이썬(7)-matplotlib (0) | 2024.05.27 |
| 파이썬(6)-Pandas(2) (0) | 2024.05.27 |
| 파이썬(6)-Pandas(1) (0) | 2024.05.27 |



