
*이 글을 읽기전에 작성자 개인의견이 있으니, 다른 블로그와 교차로 읽는것을 권장합니다.*
1. Clusters(클러스터)
- 유사한 특성을 가진 개체들의 집합
- 고객 분류, 유전자 분석, 이미지 분할
- 데이터 세트를 여러 개의 하위 집합(군집)으로 나누는 방법
주요 개념
1-1. 군집(Cluster):
- 데이터 포인트들의 모임으로, 같은 클러스터 내의 데이터 포인트들은 서로 유사한 특성을 가지고 있습니다.
- 서로 다른 클러스터의 데이터 포인트들은 상대적으로 다른 특성을 가집니다.
1-2. 비지도 학습(Unsupervised Learning):
- 클러스터링은 비지도 학습의 일종으로, 데이터에 대한 레이블이 제공되지 않고 데이터 자체의 구조를 발견하는 것을 목표로 합니다.
클러스터링 알고리즘 종류
1-3. K-평균 클러스터링(K-Means Clustering):
- 데이터 세트를 사전에 정의된 K개의 클러스터로 나눕니다.
- 각 클러스터는 중심점(센트로이드)을 가지며, 데이터 포인트는 가장 가까운 센트로이드에 할당됩니다.
1-4. 계층적 클러스터링(Hierarchical Clustering):
- 데이터 포인트들을 계층적으로 나누거나 병합하여 클러스터를 형성합니다.
- 덴드로그램(Dendrogram)을 통해 클러스터링 과정을 시각화할 수 있습니다.
1-5. 밀도 기반 클러스터링(DBSCAN, Density-Based Spatial Clustering of Applications with Noise):
- 데이터 포인트의 밀도를 기준으로 클러스터를 형성합니다.
- 밀도가 높은 영역에서 클러스터를 찾고, 밀도가 낮은 포인트들은 노이즈로 간주합니다.
1-6. 가우시안 혼합 모델(Gaussian Mixture Model, GMM):
- 데이터가 여러 개의 가우시안 분포로부터 생성되었다고 가정하고, 각 가우시안 분포를 클러스터로 간주합니다.
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
X, y = make_blobs(n_samples=100, centers=3, random_state=2023)
X = pd.DataFrame(X)
Xysns.scatterplot(x=X[0], y=X[1], hue=y)k-평균 군집 모듈
from sklearn.cluster import KMeans
km = KMeans(n_clusters=3)
# k=3개
km.fit(X)
pred=km.predict(X)sns.scatterplot(x=X[0], y=X[1], hue=pred)km = KMeans(n_clusters=5)
# k=5개
km.fit(X)
pred=km.predict(X)sns.scatterplot(x=X[0], y=X[1], hue=pred)# 평가값: 하나의 클러스터안에 중심점으로부터 각각의 데이터 거리를 합한 값의 평균
km.inertia_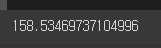
inertia_list = []
for i in range(2,11):
km = KMeans(n_clusters=i)
km.fit(X)
inertia_list.append(km.inertia_)
inertia_list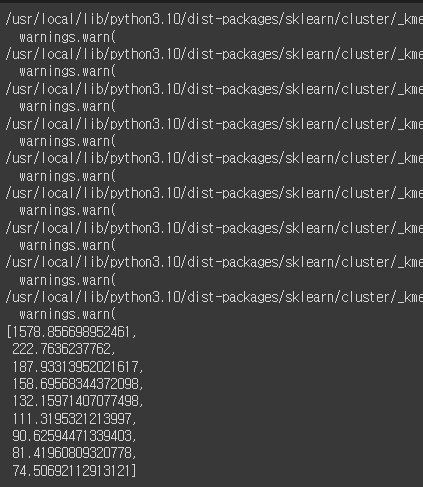
sns.lineplot(x=range(2,11), y=inertia_list) # 엘보우 메서드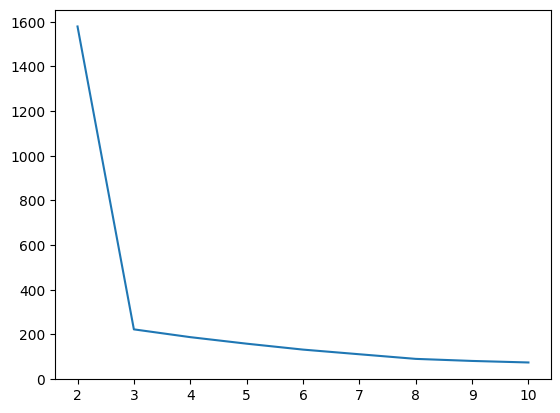
2. marketing 데이터셋
mkt_df = pd.read_csv('/content/drive/MyDrive/KDT/6. 머신러닝과 딥러닝/Data/marketing.csv')
mkt_df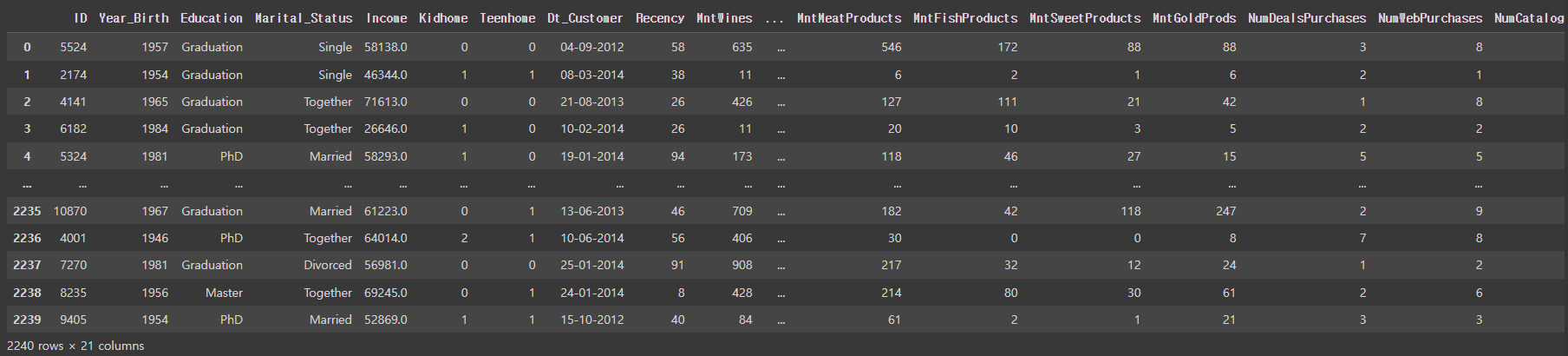
mkt_df.info()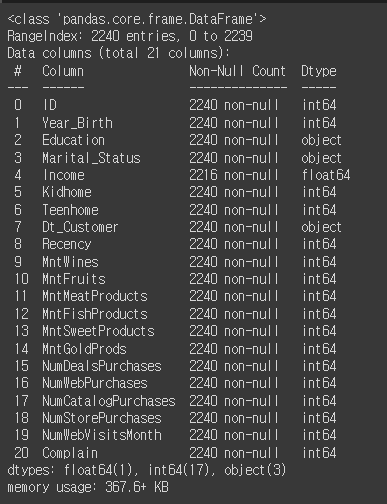
- ID: 고객 아이디
- Year_Birth: 출생 연도
- Education: 학력
- Marital_Status: 결혼 여부
- Income: 소득
- Kidhome: 어린이 수
- Teenhome: 청소년 수
- Dt_Customer: 고객 등록일
- Recency: 마지막 구매일로부터 경과일
- MntWines: 와인 구매액
- MntFruits: 과일 구매액
- MntMeatProducts: 육류 구매액
- MntFishProducts: 어류 구매액
- MntSweetProducts: 단맛 제품 구매액
- MntGoldProds: 골드 제품 구매액
- NumDealsPurchases: 할인 행사 구매 수
- NumWebPurchases: 웹에서 구매 수
- NumCatalogPurchases: 카탈로그에서 구매 수
- NumStorePurchases: 매장에서의 구매 수
- NumWebVisitsMonth: 월별 웹 방문 수
- Complain: 불만 여부
mkt_df.drop('ID', axis=1, inplace=True)
mkt_df.describe()
mkt_df.sort_values('Year_Birth')
mkt_df.sort_values('Income', ascending=False)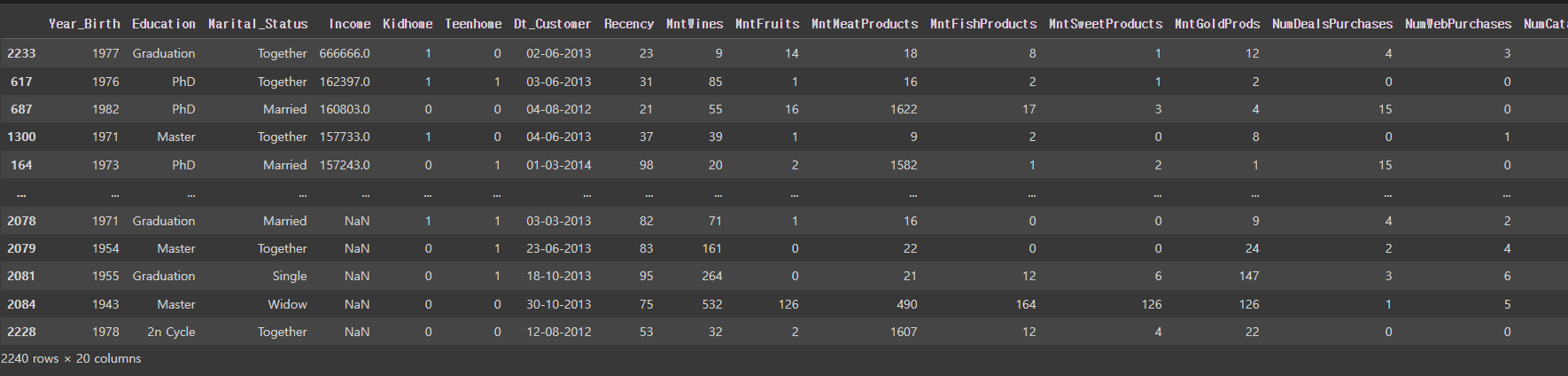
# mkt_df = mkt_df[mkt_df['Income'] < 200000] # NaN은 저장되지 않음
# 범위를 주면 생기는 문제, NaN이 다 날라가버림
mkt_df = mkt_df[mkt_df['Income'] != 666666]mkt_df.head(10)
mkt_df.isna().mean()
mkt_df = mkt_df.dropna()
mkt_df.isna().mean()
mkt_df.info()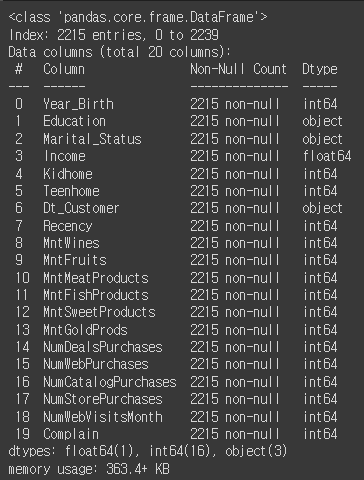
mkt_df['Dt_Customer'] = pd.to_datetime(mkt_df['Dt_Customer'], format='%d-%m-%Y')
mkt_df.info()
# 마지막으로 가입된 사람을 기준으로 현재 데이터의 가입 날짜(달)의 차를 구하기
# pass_month
mkt_df['pass_month'] = (mkt_df['Dt_Customer'].max().year * 12 + mkt_df['Dt_Customer'].max().month) - (mkt_df['Dt_Customer'].dt.year * 12 + mkt_df['Dt_Customer'].dt.month)
mkt_df.head()
mkt_df.drop('Dt_Customer', axis=1, inplace=True)
mkt_df.head()
# 와인 + 과일 + 육류 + 어류 + 단맛 + 골드
# Total_mnt
mkt_df['Total_mnt'] = mkt_df[['MntWines', 'MntFruits', 'MntMeatProducts', 'MntFishProducts', 'MntSweetProducts', 'MntGoldProds']].sum(axis=1)
mkt_df.head()
pd.set_option('display.max_column', 30)
# column 더보기
mkt_df.head()
mkt_df.info()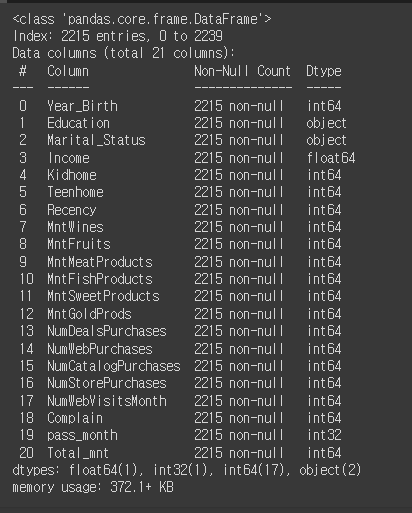
mkt_df['Children'] = mkt_df[['Kidhome', 'Teenhome']].sum(axis=1)
mkt_df.head()
mkt_df.drop(['Kidhome', 'Teenhome'], axis=1, inplace=True)
mkt_df['Education'].value_counts()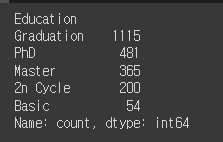
# 텍스트 데이터
mkt_df['Marital_Status'] = mkt_df['Marital_Status'].replace({
'Married':'Partner',
'Together':'Partner',
'Single':'Single',
'Divorced':'Single',
'Widow':'Single',
'Alone':'Single',
'Absurd':'Single',
'YOLO':'Single'
})
mkt_df['Marital_Status'].value_counts()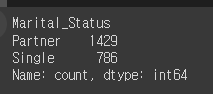
mkt_df.info()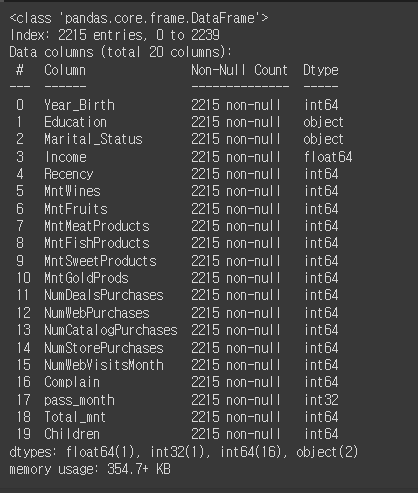
mkt_df = pd.get_dummies(mkt_df, columns=['Education', 'Marital_Status'])
mkt_df.head()
from sklearn.preprocessing import StandardScaler
# 데이터 표준화 -> N(0,1) 모델
ss = StandardScaler()
ss.fit_transform(mkt_df)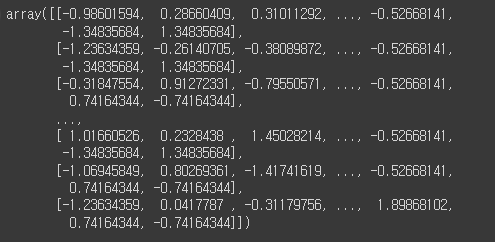
pd.DataFrame(ss.fit_transform(mkt_df))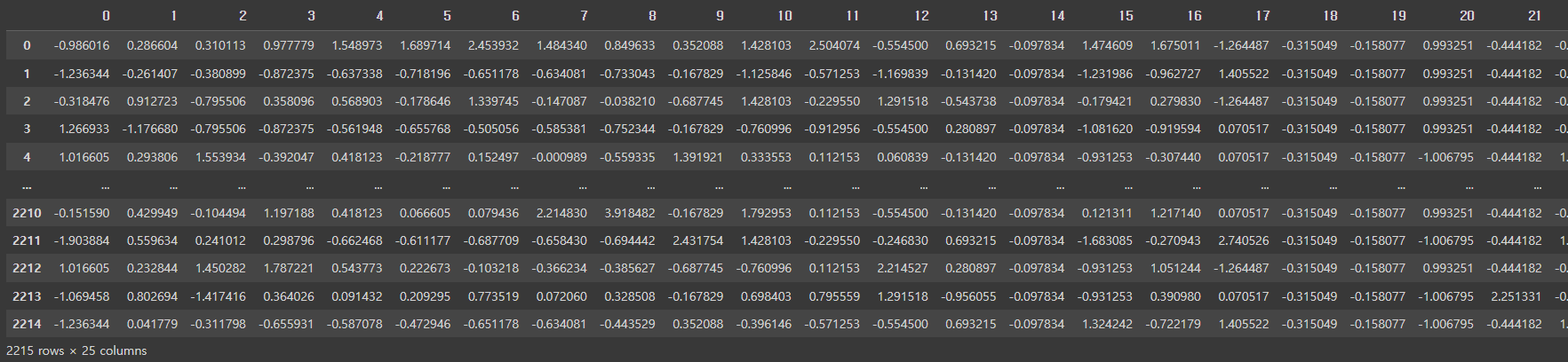
ss_df = pd.DataFrame(ss.fit_transform(mkt_df), columns=mkt_df.columns)
ss_df
# 전처리할때 다른때랑 같이한것은 스케일링한것, 강조하고싶은것을 파생변수로 만들어서 추가로 강조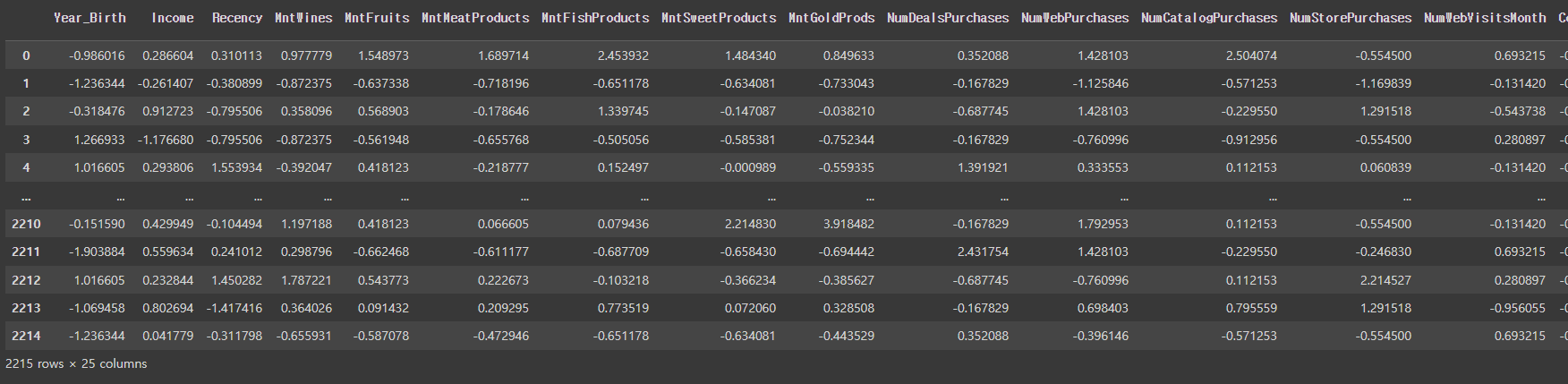
3. KMeans
- k개의 중심점을 찍은 후에 이 중심점에서 각 점간의 거리의 합이 가장 최소가 되는 중심점 k의 위치를 찾고, 이 중심점에서 가까운 점들을 기준으로 묶는 알고리즘
- k개의 클러스터의 수는 정해줘야 함
inertia_list = []
for i in range(2,11):
km = KMeans(n_clusters=i, random_state=2024)
km.fit(ss_df)
inertia_list.append(km.inertia_)
inertia_list
sns.lineplot(x=range(2,11), y=inertia_list)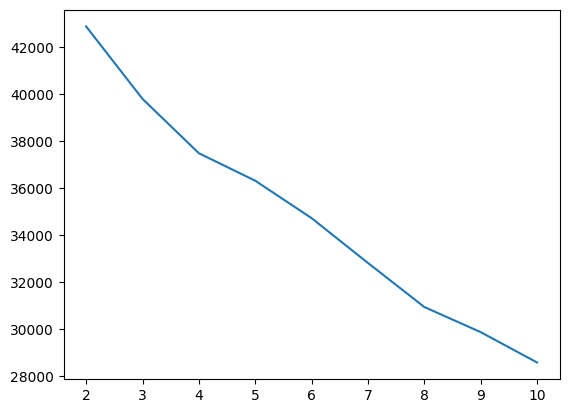
4. 실루엣 스코어(Silhouette Score)
- 군집화의 품질을 평가하는 지표로, 각 데이터 포인트가 자신이 속한 군집과 얼마나 잘 맞는지, 그리고 다른 군집과 얼마나 잘 구분되는지를 측정
- -1에서 1사이의 값을 가지며, 값이 클수록 군집화의 품질이 높음을 나타냄
from sklearn.metrics import silhouette_score # 실루엣스코어 모듈
score = []
for i in range(2,11):
km = KMeans(n_clusters=i, random_state=2024)
km.fit(ss_df)
pred = km.predict(ss_df)
score.append(silhouette_score(ss_df, pred))
score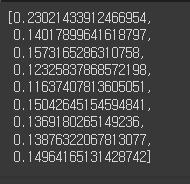
sns.lineplot(x=range(2,11), y=score)
# 처음에 떨어지는 부분은 군집에서 나눠지는 부분
# 급격히 가중치 올라가는 부분(4)이 k개수로 판단 -> k=4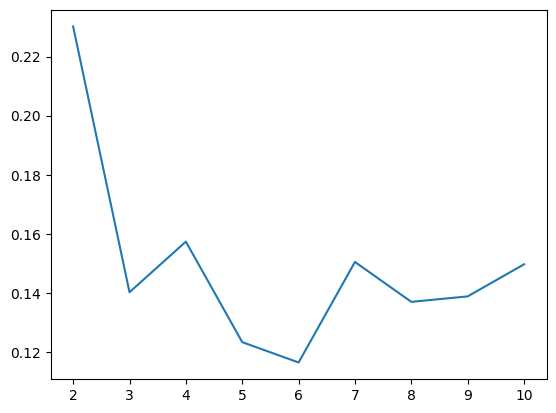
km = KMeans(n_clusters=4, random_state=2024)
km.fit(ss_df)
pred = km.predict(ss_df)
pred
mkt_df['label'] = pred
mkt_df
# 고객에 대한 class 생성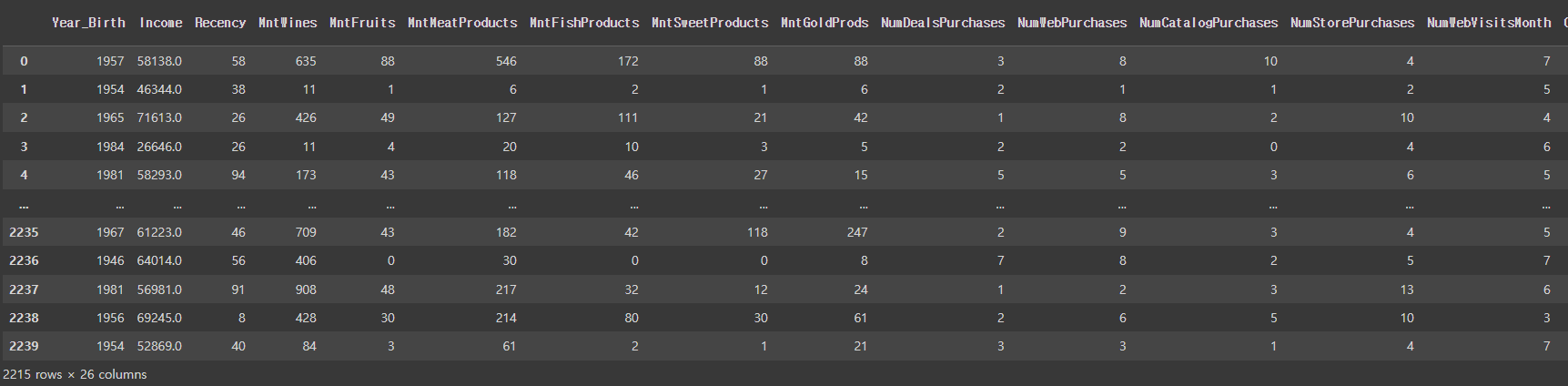
mkt_df['label'].value_counts()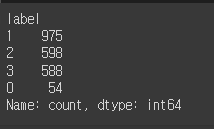
'Python > 머신러닝(ML)' 카테고리의 다른 글
| Python(29)- 파이토치로 선형회귀 구현 (0) | 2024.06.20 |
|---|---|
| Python(28)- 파이토치 (0) | 2024.06.19 |
| Python(26)- 다양한 모델 적용 (0) | 2024.06.19 |
| Python(25)- LightGBM (0) | 2024.06.19 |
| Python(24)- 앙상블 모델(Ensemble), 랜덤 포레스트(Random Forest) (0) | 2024.06.19 |



