
*이 글을 읽기전에 작성자 개인의견이 있으니, 다른 블로그와 교차로 읽는것을 권장합니다.*
데이터 전처리
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
from sklearn.preprocessing import LabelEncoder # 원핫인코딩 이전 라벨인코딩(문자->숫자) 모듈
from sklearn.feature_extraction.text import CountVectorizer # # 텍스트를 벡터화
from torch.utils.data import DataLoader, Dataset
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_scorenewsgroups_data = fetch_20newsgroups(subset='all')
texts, labels = newsgroups_data.data, newsgroups_data.targetlabels
# 위에서 받은 데이터를 학습시키고 데이터를 분리하기
label_encoder = LabelEncoder()
labels = label_encoder.fit_transform(labels)
# 학습 : 8, 테스트: 2로 분리
X_train, X_test, y_train, y_test = train_test_split(texts, labels, test_size=0.2, random_state=2024)# 텍스트 데이터는 벡터화
# r'\b\w+\b' : row스트링
# r : \해석하지 않게 함
# \b : 단어의 시작 또는 끝을 의미, 공백, .인식하게 만들어줌
# \w : 단어 문자를 의미
vectorizer = CountVectorizer(max_features=10000, token_pattern=r'\b\w+\b')
X_train = vectorizer.fit_transform(X_train).toarray()
X_test = vectorizer.transform(X_test).toarray()# 파이토치 텐서로 변환
X_train_tensor = torch.tensor(X_train, dtype=torch.float32)
X_test_tensor = torch.tensor(X_test, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train, dtype=torch.long) # y값 형식은 long변환
y_test_tensor = torch.tensor(y_test, dtype=torch.long)# 데이터셋 클래스 정의
class NewsGroupDataset(Dataset):
def __init__(self, X, y):
self.X = X
self.y = y
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
return self.X[idx], self.y[idx]train_dataset = NewsGroupDataset(X_train_tensor, y_train_tensor)
test_dataset = NewsGroupDataset(X_test_tensor, y_test_tensor)len(train_dataset)
train_dataset[0]
# 데이터로더 생성
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)RNN 모델 생성
# RNN 모델 생성
class RNNModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=1):
super(RNNModel, self).__init__()
self.hidden_size = hidden_size
self.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
h = torch.zeros(1, x.size(0), self.hidden_size).to(x.device)
out, _ = self.rnn(x, h)
out = self.fc(out[:, -1, :])
return out
input_size = 10000
hidden_size = 128
output_size = len(label_encoder.classes_)
num_layers = 1
model = RNNModel(input_size, hidden_size, output_size, num_layers)
model = model.to('cuda' if torch.cuda.is_available() else 'cpu')loss_fun = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 학습
num_epochs = 10
for epoch in range(num_epochs):
model.train()
for X_batch, y_batch in train_loader:
X_batch = X_batch.unsqueeze(1)
# X_batch, y_batch = X_batch.to(model.device), y_batch.to(model.device)
outputs = model(X_batch)
loss = loss_fun(outputs, y_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'Epoch: {epoch+1}/{num_epochs}, Loss: {loss.item():.4f}')
# accuracy로 모델평가
model.eval()
y_test, y_pred = [], []
with torch.no_grad():
for X_batch, y_batch in test_loader:
X_batch = X_batch.unsqueeze(1)
outputs = model(X_batch)
_, pred = torch.max(outputs, 1)
y_test.extend(y_batch.detach().numpy())
y_pred.extend(pred.detach().numpy())
accuracy = accuracy_score(y_test, y_pred)
print(f'accuracy: {accuracy:.4f}')
1. LSTM(Long Short-Term Memory)
- 바닐라 RNN은 시퀀스 데이터를 처리할 때, 시간이 지남에 따라 정보가 소실되거나 기울기(가중치) 소실 문제가 발생 (RNN 장기의존성 문제)


Wx는 x가중치, Wh는 h시점 가중치 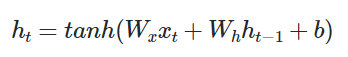
위 그림과 대조하면 하이퍼볼릭탄젠트는 xt시점에서 가중치를 넣었을 때, 이전 ht-1*Wh(가중치h)로 인해 ht가 다음 가중치 발생 - LSTM은 순환 신경망(RNN)의 한 종류로, 긴 시퀀스 데이터를 효과적으로 학습할 수 있도록 고안된 구조
- 위키독스 8-2 장단기 메모리 참조
- LSTM은 은닉층의 메모리 셀에 입력 게이트, 망각 게이트, 출력 게이트를 추가하여 불필요한 기억을 지우고, 기억해야할 것들을 정합니다


1-1. LSTM의 구조

- 입력 게이트 : 현재 입력값과 이전의 은닉 상태를 사용하여 어떤 정보를 새롭게 저장할지 결정, 현재 정보를 기억하기 위한 게이트


- 망각(삭제) 게이트 : 현재 입력값과 이전의 은닉 상태를 사용하여 어떤 정보를 잊을지(삭제) 결정


- 셀 상태 : 정보가 직접 흐르는 경로로, 정보가 소실되지 않도록 함

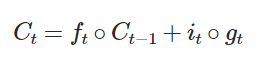
-
- 같은 크기의 두 행렬이 있을 때 같은 위치의 성분끼리 곱을 ∘ 표현, 입력 게이트에서 선택된 기억을 삭제 게이트의 결과값과 더하고 이 값을 현재 시점 t의 셀 상태라고 하며, 이 값은 다음 t+1 시점의 LSTM 셀로 넘기기
- 삭제 게이트는 이전 시점의 입력을 얼마나 반영할지를 의미하고, 입력 게이트는 현재 시점의 입력을 얼마나 반영할지를 결정
- 출력 게이트 : 현재 입력값과 이전의 은닉 상태를 사용하여 다음의 은닉 상태를 결정

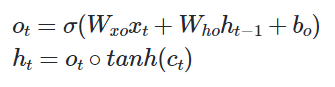
- 현재 시점 t의 𝑥값과 이전 시점 t-1의 은닉 상태가 시그모이드 함수를 지난 값(-1~1), 해당 값은 값이 걸러지는 효과가 발생하여 은닉 상태로 변함
1-2. LSTM으로 예제 변환
위의 RNN모델 코드 가져와 LSTM으로 변경
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
from sklearn.preprocessing import LabelEncoder
from sklearn.feature_extraction.text import CountVectorizer
from torch.utils.data import DataLoader, Dataset
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
newsgroups_data = fetch_20newsgroups(subset='all')
texts, labels = newsgroups_data.data, newsgroups_data.target
label_encoder = LabelEncoder()
labels = label_encoder.fit_transform(labels)
X_train, X_test, y_train, y_test = train_test_split(texts, labels, test_size=0.2, random_state=2024)
vectorizer = CountVectorizer(max_features=10000, token_pattern=r'\b\w+\b')
X_train = vectorizer.fit_transform(X_train).toarray()
X_test = vectorizer.transform(X_test).toarray()
X_train_tensor = torch.tensor(X_train, dtype=torch.float32)
X_test_tensor = torch.tensor(X_test, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train, dtype=torch.long)
y_test_tensor = torch.tensor(y_test, dtype=torch.long)
class NewsGroupDataset(Dataset):
def __init__(self, X, y):
self.X = X
self.y = y
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
return self.X[idx], self.y[idx]
train_dataset = NewsGroupDataset(X_train_tensor, y_train_tensor)
test_dataset = NewsGroupDataset(X_test_tensor, y_test_tensor)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
class LSTMModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=1):
super(LSTMModel, self).__init__()
self.hidden_size = hidden_size
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
h = torch.zeros(1, x.size(0), self.hidden_size).to(x.device)
c = torch.zeros(1, x.size(0), self.hidden_size).to(x.device)
out, _ = self.lstm(x, (h, c))
out = self.fc(out[:, -1, :])
return out
input_size = 10000
hidden_size = 128
output_size = len(label_encoder.classes_)
num_layers = 1
model = LSTMModel(input_size, hidden_size, output_size, num_layers)
model = model.to('cuda' if torch.cuda.is_available() else 'cpu')
loss_fun = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
num_epochs = 10
for epoch in range(num_epochs):
model.train()
for X_batch, y_batch in train_loader:
X_batch = X_batch.unsqueeze(1)
# X_batch, y_batch = X_batch.to(model.device), y_batch.to(model.device)
outputs = model(X_batch)
loss = loss_fun(outputs, y_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'Epoch: {epoch+1}/{num_epochs}, Loss: {loss.item():.4f}')
model.eval()
y_test, y_pred = [], []
with torch.no_grad():
for X_batch, y_batch in test_loader:
X_batch = X_batch.unsqueeze(1)
outputs = model(X_batch)
_, pred = torch.max(outputs, 1)
y_test.extend(y_batch.detach().numpy())
y_pred.extend(pred.detach().numpy())
accuracy = accuracy_score(y_test, y_pred)
print(f'accuracy: {accuracy:.4f}')
2. GRU(Gated Recurrent Unit)
- LSTM과 유사하지만 구조가 더 간단한 RNN의 한 종류
- LSTM과 달리 셀 상태(cell state)를 가지지 않으며, 업데이트 게이트와 리셋 게이트를 사용하여 정보를 처리
- 위키독스 8-3 참고


위의 RNN모델 코드 가져와 변경
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
from sklearn.preprocessing import LabelEncoder
from sklearn.feature_extraction.text import CountVectorizer
from torch.utils.data import DataLoader, Dataset
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
newsgroups_data = fetch_20newsgroups(subset='all')
texts, labels = newsgroups_data.data, newsgroups_data.target
label_encoder = LabelEncoder()
labels = label_encoder.fit_transform(labels)
X_train, X_test, y_train, y_test = train_test_split(texts, labels, test_size=0.2, random_state=2024)
vectorizer = CountVectorizer(max_features=10000, token_pattern=r'\b\w+\b')
X_train = vectorizer.fit_transform(X_train).toarray()
X_test = vectorizer.transform(X_test).toarray()
X_train_tensor = torch.tensor(X_train, dtype=torch.float32)
X_test_tensor = torch.tensor(X_test, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train, dtype=torch.long)
y_test_tensor = torch.tensor(y_test, dtype=torch.long)
class NewsGroupDataset(Dataset):
def __init__(self, X, y):
self.X = X
self.y = y
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
return self.X[idx], self.y[idx]
train_dataset = NewsGroupDataset(X_train_tensor, y_train_tensor)
test_dataset = NewsGroupDataset(X_test_tensor, y_test_tensor)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
class GRUModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=1):
super(GRUModel, self).__init__()
self.hidden_size = hidden_size
self.gru = nn.GRU(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
h = torch.zeros(1, x.size(0), self.hidden_size).to(x.device)
out, _ = self.gru(x, h)
out = self.fc(out[:, -1, :])
return out
input_size = 10000
hidden_size = 128
output_size = len(label_encoder.classes_)
num_layers = 1
model = GRUModel(input_size, hidden_size, output_size, num_layers)
model = model.to('cuda' if torch.cuda.is_available() else 'cpu')
loss_fun = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
num_epochs = 10
for epoch in range(num_epochs):
model.train()
for X_batch, y_batch in train_loader:
X_batch = X_batch.unsqueeze(1)
# X_batch, y_batch = X_batch.to(model.device), y_batch.to(model.device)
outputs = model(X_batch)
loss = loss_fun(outputs, y_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'Epoch: {epoch+1}/{num_epochs}, Loss: {loss.item():.4f}')
model.eval()
y_test, y_pred = [], []
with torch.no_grad():
for X_batch, y_batch in test_loader:
X_batch = X_batch.unsqueeze(1)
outputs = model(X_batch)
_, pred = torch.max(outputs, 1)
y_test.extend(y_batch.detach().numpy())
y_pred.extend(pred.detach().numpy())
accuracy = accuracy_score(y_test, y_pred)
print(f'accuracy: {accuracy:.4f}')
3. LSTM vs GRU
- LSTM과 GRU는 RNN의 기울기 소실 단점(장기 의존성 문제)을 해결하기 위해 고안
- 게이트 매커니즘(삭제 게이트)을 사용하여 중요한 정보를 유지하고 불필요한 정보를 제거
- 긴 시퀀스를 효과적으로 처리할 수 있어 많은 자연어 처리 작업에서 사용
- LSTM
- 게이트 수 : 3개(입력, 망각(삭제), 출력)
- 셀 상태를 유지
- 구조가 복잡함
- 매개변수가 GRU보다 많음
- 훈련시간이 GRU보다 오래 걸림
- GRU
- 게스트 수 : 2개(업데이트, 리셋)
- 셀 상태가 없음
- 구조가 복잡함
- 매개변수가 LSTM보다 작음
- 훈련시간이 LSTM보다 적게 걸림
'Python > 자연어처리' 카테고리의 다른 글
| Python(47)- 자연어처리를 위한 모델 학습 (0) | 2024.07.15 |
|---|---|
| Python(46)- 문장 임베딩 (1) | 2024.07.05 |
| Python(44)- CNN 분류 (0) | 2024.07.02 |
| Python(43)- cbow 분류 (0) | 2024.07.02 |
| Python(42)- RNN 기초 (0) | 2024.06.27 |



