
*이 글을 읽기전에 작성자 개인의견이 있으니, 다른 블로그와 교차로 읽는것을 권장합니다.*
import urllib.request
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
from copy import deepcopy
from torch.utils.data import Dataset, DataLoader
from tqdm.auto import tqdm# 깃허브에 올라온 파일을 가져오기 위해선, filename = ''설정해줘야 함.
urllib.request.urlretrieve('https://raw.githubusercontent.com/e9t/nsmc/master/ratings_train.txt', filename='ratings_train.txt' )
urllib.request.urlretrieve('https://raw.githubusercontent.com/e9t/nsmc/master/ratings_test.txt', filename='ratings_test.txt' )train_dataset = pd.read_table('ratings_train.txt')
train_dataset
# pos, neg 비율
train_dataset['label'].value_counts()
sum(train_dataset['document'].isnull())
train_dataset['document'].isnull()
train_dataset = train_dataset[~train_dataset['document'].isnull()]
sum(train_dataset['document'].isnull())
train_dataset
Tokenization
- 자연어를 모델이 이해하기 위해서는 자연어를 숫자의 형식으로 변형시켜야함
train_dataset['document'].iloc[0].split()
vocab = set()
for doc in train_dataset['document']:
for token in doc.split():
vocab.add(token)
len(vocab)
# 단어의 빈도수 구하기
'''
[('아', 1204),
('더빙', 2),
('진짜',5929),
('짜증나네요',10),
('목소리',99),
]
'''
vocab_cnt_dict = {}
for doc in train_dataset['document']:
for token in doc.split():
if token not in vocab_cnt_dict:
vocab_cnt_dict[token] = 0
vocab_cnt_dict[token] += 1
vocab_cnt_list = [(token, cnt) for token, cnt in vocab_cnt_dict.items()]
vocab_cnt_list[:10]
top_vocabs = sorted(vocab_cnt_list, key=lambda tup:tup[1], reverse=True)
top_vocabs[:10]
cnts = [cnt for _, cnt in top_vocabs]
np.mean(cnts)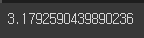
cnts[:10]
sum(np.array(cnts) > 2)
n_vocab = sum(np.array(cnts) > 2)
top_vocabs_truncated = top_vocabs[:n_vocab]
top_vocabs_truncated[:5]
vocabs = [token for token, _ in top_vocabs_truncated]
vocabs[:5]
special token
- [UNK] : Unknown Token
- [PAD] : Padding Token
unk_token = '[UNK]'
unk_token in vocabs
pad_token = '[PAD]'
pad_token in vocabs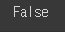
vocabs.insert(0, unk_token)
vocabs.insert(0, pad_token)
vocabs[:5]
idx_to_token = vocabs
token_to_idx = {token: i for i, token in enumerate(idx_to_token)}class Tokenizer:
def __init__(self, vocabs, use_padding=True, max_padding=64, pad_token='[PAD]', unk_token='[UNK]'):
self.idx_to_token = vocabs
self.token_to_idx = {token: i for i, token in enumerate(self.idx_to_token)}
self.use_padding = use_padding
self.max_padding = max_padding
self.pad_token = pad_token
self.unk_token = unk_token
self.unk_token_idx = self.token_to_idx[self.unk_token]
self.pad_token_idx = self.token_to_idx[self.pad_token]
def __call__(self, x:str):
token_ids = []
token_list = x.split()
for token in token_list:
if token in self.token_to_idx:
token_idx = self.token_to_idx[token]
else:
token_idx = self.unk_token_idx
token_ids.append(token_idx)
if self.use_padding:
token_ids = token_ids[:self.max_padding]
n_pads = self.max_padding - len(token_ids)
token_ids = token_ids + [self.pad_token_idx] * n_pads
return token_idstokenizer = Tokenizer(vocabs, use_padding=False)
sample = train_dataset['document'].iloc[0]
print(sample)
tokenizer(sample) # [51, 1, 5, 10485, 1064]
token_length_list = []
for sample in train_dataset['document']:
token_length_list.append(len(tokenizer(sample)))
plt.hist(token_length_list)
plt.xlabel('token length')
plt.ylabel('count')
max(token_length_list)
tokenizer = Tokenizer(vocabs, use_padding=True, max_padding=50)
print(tokenizer(sample)) # 데이터로더, 배치사이즈, 데이터셋 필요
train_valid_dataset = pd.read_table('ratings_train.txt')
test_dataset = pd.read_table('ratings_test.txt')
print(f'train, valid samples: {len(train_valid_dataset)}')
print(f'test samples: {len(test_dataset)}')
train_valid_dataset.head()
train_valid_dataset = train_valid_dataset.sample(frac=1.)
train_valid_dataset.head()
train_ratio = 0.8
n_train = int(len(train_valid_dataset) * train_ratio)
train_df = train_valid_dataset[:n_train]
valid_df = train_valid_dataset[n_train:]
test_df = test_dataset
print(f'train samples: {len(train_df)}')
print(f'valid samples: {len(valid_df)}')
print(f'test samples: {len(test_df)}')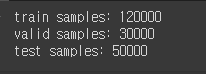
# 1/10으로 샘플링
train_df = train_df.sample(frac=0.8)
valid_df = valid_df.sample(frac=0.8)
test_df = test_df.sample(frac=0.8)
print(f'train samples: {len(train_df)}')
print(f'valid samples: {len(valid_df)}')
print(f'test samples: {len(test_df)}')
class NSMCDataset(Dataset):
def __init__(self, data_df, tokenizer=None):
self.data_df = data_df
self.tokenizer = tokenizer
def __len__(self):
return len(self.data_df)
def __getitem__(self, idx):
sample_raw = self.data_df.iloc[idx]
sample = {}
sample['doc'] = str(sample_raw['document'])
sample['label'] = int(sample_raw['label'])
if self.tokenizer is not None:
sample['doc_ids'] = self.tokenizer(sample['doc'])
return sampletrain_dataset = NSMCDataset(data_df=train_df, tokenizer=tokenizer)
valid_dataset = NSMCDataset(data_df=valid_df, tokenizer=tokenizer)
test_dataset = NSMCDataset(data_df=test_df, tokenizer=tokenizer)
print(train_dataset[0])
def collate_fn(batch):
keys = [key for key in batch[0].keys()]
data = {key: [] for key in keys}
for item in batch:
for key in keys:
data[key].append(item[key])
return datatrain_dataloader = DataLoader(
train_dataset,
batch_size=128,
collate_fn=collate_fn, # 배치사이즈를 어떻게 묶을것인가
shuffle=True
)
valid_dataloader = DataLoader(
valid_dataset,
batch_size=128,
collate_fn=collate_fn,
shuffle=False
)
test_dataloader = DataLoader(
test_dataset,
batch_size=128,
collate_fn=collate_fn,
shuffle=False
)sample = next(iter(test_dataloader))
sample.keys() # dict_keys(['doc', 'label', 'doc_ids'])
sample['doc'][3] # 정말 재미지게 오랫동안 보게되는 드라마
print(sample['doc_ids'][3]) # [4, 17366, 2223, 2798, 52, 0, ... 0]
CBOW(Continuous Bag of Words)

- 자연어 처리에서 단어의 의미를 벡터로 표현하는 Word2Vec 임베딩모델 중 하나
- 문맥(context) 단어들을 사용해서 타겟(target) 단어를 예측하는 것(주변단어->중심단어)
- 모델의 원리
- 문장은 단어의 연속으로 구성
- 예) The cat sat on the mat
- 타겟단어 : cat, 주변단어 : (The, sat)
- 문맥 단어의 수를 결정하는 윈도우 크기를 설정
- 예) 윈도우 크기 : 2, 타겟 단어의 왼쪽과 오른쪽에서 각각 2개의 단어를 문맥 단어로 사용
- 모든 단어를 고유한 인덱스로 매핑하고 원 핫 인코딩으로 변환
- 입력으로 주어진 문맥 단어들을 이용해 타겟 단어를 예측하는 신경망을 학습
- 예) 일반적으로 입력층, 은닉층, 출력층 3개의 층으로 구성
- 입력층(Input Layer) : 문맥 단어들(중심단어)의 원 핫 인코딩 벡터를 받음, 입력 벡터의 차원으로, 단어집합의 크기(=어휘 크기)와 동일.
- ex) 어휘 크기 = 10,000이라면 input_size = 10,000
- 은닉층(Hidden Layer) : : 입력 벡터들의 평균을 계산하여 은닉층 벡터를 만듦, 입력층과 출력층 사이에 위치하며, 단어 임베딩 학습, 은닉층의 뉴런 수는 임베딩 벡터 크기와 동일
- ex) 임베딩 벡터 차원 = 300라면 hidden_size = 300
- 출력층(Output Layer) : 은닉층 벡터를 사용해 타겟 단어(중심단어)를 입력으로 받아 소프트맥스 함수를 통해 중심단어 확률 분포 출력, 중심 단어를 예측하기 위한 출력 벡터 차원, 출력층의 뉴런 수는 입력층과 동일
- 문장은 단어의 연속으로 구성
cbow 모델 학습 과정
1.데이터 준비 :
- 문장을 단어로 토큰화, 윈도우 크기(주변단어 수)에 따라 주변-중심 단어 쌍 생성
- 주변 단어는 원핫 인코딩으로 입력 벡터 변환

2. 입력층 :


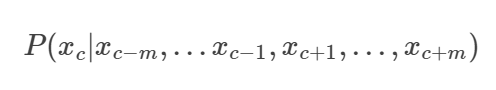
3. 은닉층 :
- 입력 벡터들이 은닉층을 거치면서 임베딩 벡터로 변환
- 입력 벡터 X 가중치 W 행렬 = 임베딩 벡터, w의 각 행을 각 단어의 임베딩 벡터로 사용
- 입력 벡터의 평균을 구해서 하나의 임베딩 벡터 제작



4. 출력층 :
- 은닉층의 임베딩 벡터가 출력층으로 전달, 소프트맥스 함수에 의해 중심단어의 확률분포로 변환


5. 손실함수 및 역전파 :
- 출력 확률분포와 실제 중심단어의 원핫인코딩 벡터간의 교차 엔트로피 손실 계산
- 역전파를 통해 손실 최소화하도록 가중치를 업데이트하여 최적의 output 뽑기





class CBOW(nn.Module):
def __init__(self, vocab_size, embed_dim):
super().__init__()
self.output_dim = embed_dim
self.embeddings = nn.Embedding(vocab_size, embed_dim, padding_idx=0)
def forward(self, x):
# (batch_size, sequence) -> (batch_size, sequence, embed_dim)
x_embeded = self.embeddings(x)
stnc_repr = torch.mean(x_embeded, dim=1) # batch_size * embed_dim
return stnc_reprclass Classifier(nn.Module):
def __init__(self, sr_model, output_dim, vocab_size, embed_dim, **kwargs):
super().__init__()
self.sr_model = sr_model(vocab_size=vocab_size, embed_dim=embed_dim, **kwargs)
self.input_dim = self.sr_model.output_dim
self.output_dim = output_dim
self.fc = nn.Linear(self.input_dim, self.output_dim)
def forward(self, x):
return self.fc(self.sr_model(x))model = Classifier(sr_model=CBOW, output_dim=2, vocab_size=len(vocabs), embed_dim=16)
model.sr_model.embeddings.weight[0]
use_cuda = True and torch.cuda.is_available()
if use_cuda:
model.cuda()
optimizer = optim.Adam(params=model.parameters(), lr=0.01)
calc_loss = nn.CrossEntropyLoss()n_epoch = 10
global_i = 0
valid_loss_history = []
train_loss_history = []
best_model = None
best_epoch_i = None
min_valid_loss = 9e+9
for epoch_i in range(n_epoch):
model.train()
for batch in train_dataloader:
optimizer.zero_grad()
X = torch.tensor(batch['doc_ids'])
y = torch.tensor(batch['label'])
if use_cuda:
X = X.cuda()
y = y.cuda()
y_pred = model(X)
loss = calc_loss(y_pred, y)
if global_i % 1000 == 0:
print(f'i: {global_i}, epoch: {epoch_i}, loss: {loss.item()}')
train_loss_history.append((global_i, loss.item()))
loss.backward()
optimizer.step()
global_i += 1
model.eval()
valid_loss_list = []
for batch in valid_dataloader:
X = torch.tensor(batch['doc_ids'])
y = torch.tensor(batch['label'])
if use_cuda:
X = X.cuda()
y = y.cuda()
y_pred = model(X)
loss = calc_loss(y_pred, y)
valid_loss_list.append(loss.item())
valid_loss_mean = np.mean(valid_loss_list)
valid_loss_history.append((global_i, valid_loss_mean.item()))
if valid_loss_mean < min_valid_loss:
min_valid_loss = valid_loss_mean
best_epoch_i = epoch_i
best_model = deepcopy(model)
if epoch_i % 2 == 0:
print("*"*30)
print(f'valid_loss_mean: {valid_loss_mean}')
print("*"*30)
print(f'best_epoch: {best_epoch_i}')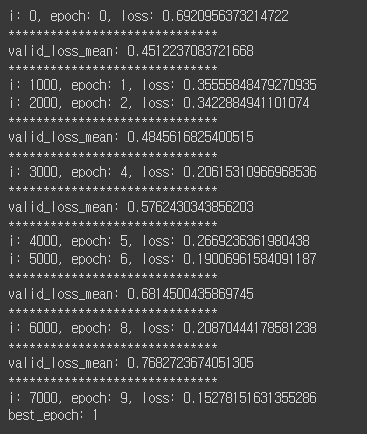
def calc_moving_average(arr, win_size=100):
new_arr = []
win = []
for i, val in enumerate(arr):
win.append(val)
if len(win) > win_size:
win.pop(0)
new_arr.append(np.mean(win))
return np.array(new_arr)valid_loss_history = np.array(valid_loss_history)
train_loss_history = np.array(train_loss_history)
plt.figure(figsize=(12,8))
plt.plot(train_loss_history[:,0],
calc_moving_average(train_loss_history[:,1]), color='blue')
plt.plot(valid_loss_history[:,0],
valid_loss_history[:,1], color='red')
plt.xlabel("step")
plt.ylabel("loss")
Evaluation
model = best_model
model.eval()
total = 0
correct = 0
for batch in tqdm(test_dataloader,
total=len(test_dataloader.dataset)//test_dataloader.batch_size):
X = torch.tensor(batch['doc_ids'])
y = torch.tensor(batch['label'])
if use_cuda:
X = X.cuda()
y = y.cuda()
y_pred = model(X)
curr_correct = y_pred.argmax(dim=1) == y
total += len(curr_correct)
correct += sum(curr_correct)
print(f'test accuracy: {correct/total}')
'Python > 자연어처리' 카테고리의 다른 글
| Python(45)- LSTM과 GRU (0) | 2024.07.02 |
|---|---|
| Python(44)- CNN 분류 (0) | 2024.07.02 |
| Python(42)- RNN 기초 (0) | 2024.06.27 |
| Python(41)- 워드 임베딩 시각화 (0) | 2024.06.27 |
| Python(40)- 워드 임베딩 (0) | 2024.06.25 |



