
*이 글을 읽기전에 작성자 개인의견이 있으니, 다른 블로그와 교차로 읽는것을 권장합니다.*
1. 네이버 영화 리뷰 데이터셋
총 200,000개의 리뷰로 구성된 데이터로 영화 리뷰를 긍/부정으로 분류하기 위해 만들어진 데이터셋
리뷰가 긍정인 경우 1, 부정인 경우 0으로 표시한 레이블로 구성되어 있음
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf
import urllib.request
import pandas as pd# 깃허브에 올라온 파일을 가져오기 위해선, filename = ''설정해줘야 함.
urllib.request.urlretrieve('https://raw.githubusercontent.com/e9t/nsmc/master/ratings_train.txt', filename='ratings_train.txt' )
urllib.request.urlretrieve('https://raw.githubusercontent.com/e9t/nsmc/master/ratings_test.txt', filename='ratings_test.txt' )

train_dataset = pd.read_table('ratings_train.txt')
train_dataset일반적인 구분자로 구분된 파일을 DataFrame으로 읽어들이는 데 사용, pd.read_csv()와 비슷하지만, 기본 구분자가 '\t' (탭)이라는 점이 다릅니다. 이 함수는 다양한 형식과 인코딩의 입력 파일을 처리하기 위해 여러 매개변수를 지정할 수 있도록 매우 유연합니다.

len(train_dataset)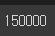
2. 데이터 전처리
# 결측치를 확인하고 결측치를 제거하기
train_dataset.replace('', float('NaN'), inplace=True) # 결측치 -> True 반환
# any() : 배열에서 하나라도 True가 존재하는지 확인
train_dataset.isnull().values.any() # values : value값 -> ndarray
# 5개 날라감
train_dataset = train_dataset.dropna().reset_index(drop=True)
len(train_dataset)
# 열(document)을 기준으로 중복 데이터를 제거
# drop_duplicates() : duplicate가 중복이란 뜻으로, 중복제거
train_dataset = train_dataset.drop_duplicates(subset=['document']).reset_index(drop=True)
len(train_dataset)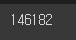
# 한글이 아닌 문자를 포함하는 데이터를 제거하기
# str.replace() : 문자열 대체
# regex=True 옵션을 사용하여 정규 표현식(패턴)을 인식
# '[^ㄱ-ㅎㅏ-ㅣ가-힣]'는 한글 문자 범위를 제외한 모든 문자를 공백으로 치환
train_dataset['document'] = train_dataset['document'].str.replace('[^ㄱ-ㅎㅏ-ㅣ가-힣]', ' ', regex=True)
train_dataset
# 너무 짧은 단어를 제거하기(한 글자 이하는 제거)
# apply() : 함수 적용
# lambda함수를 이용해서 두 글자 이상만 설정
train_dataset['document'] = train_dataset['document'].apply(lambda x: ' '.join([token for token in x.split() if len(token) > 1]))
train_dataset
# 전체 길이가 50자 이하이거나 전체 단어의 개수가 3개 이하인 데이터를 제거하기
# 전체 길이 51자 이상, 4개 이상으로 대체
# reset_index(drop=True) : 인덱스를 다시 설정하고 기존 인덱스를 버리는 역할
train_dataset = train_dataset[train_dataset.document.apply(lambda x: len(str(x)) > 50 and len(str(x).split()) > 3)].reset_index(drop=True)
len(train_dataset)
train_dataset
!pip install konlpy
from konlpy.tag import Okt # 한국어 자연어처리 형태소분석기# 불용어를 확인하고 불용어는 제거하기
stopwords = ['아', '휴', '아이구', '아이쿠', '아이고', '어', '나', '우리', '저희', '따라', '의해', '을', '를', '에', '의', '가', '으로', '로', '에게', '뿐이다', '의거하여', '근거하여', '입각하여', '기준으로', '예하면', '예를', '들면', '예를', '들자면', '저', '소인', '소생', '저희', '지말고', '하지마', '하지마라', '다른', '물론', '또한', '그리고', '비길수', '없다', '해서는', '안된다', '뿐만', '아니라', '만이', '아니다', '만은', '아니다', '막론하고', '관계없이', '그치지', '않다', '그러나', '그런데', '하지만', '든간에', '논하지', '않다', '따지지', '않다', '설사', '비록', '더라도', '아니면', '만', '못하다', '하는', '편이', '낫다', '불문하고', '향하여', '향해서', '향하다', '쪽으로', '틈타', '이용하여', '타다', '오르다', '제외하고', '이', '외에', '이', '밖에', '하여야', '비로소', '한다면', '몰라도', '외에도', '이곳', '여기', '부터', '기점으로', '따라서', '할', '생각이다', '하려고하다', '이리하여', '그리하여', '그렇게', '함으로써', '하지만', '일때', '할때', '앞에서', '중에서', '보는데서', '으로써', '로써', '까지', '해야한다', '일것이다', '반드시', '할줄알다', '할수있다', '할수있어', '임에', '틀림없다', '한다면', '등', '등등', '제', '겨우', '단지', '다만', '할뿐', '딩동', '댕그', '대해서', '대하여', '대하면', '훨씬', '얼마나', '얼마만큼', '얼마큼']train_dataset = list(train_dataset['document'])
print(train_dataset)
okt = Okt()
tokenized_data = []
for sentence in train_dataset:
# okt.morphs : 형태소 단위 분석, 어간 추출
# stem=True : 단어의 기본형(어간)으로 변환, 형태소 추출
# ex) 공부하는 -> 공부하다
tokenized_sentence = okt.morphs(sentence, stem=True)
stopwords_removed_sentence = [word for word in tokenized_sentence if not word in stopwords] # 불용어 제거
tokenized_data.append(stopwords_removed_sentence)okt.morphs : 형태소 단위 분석, 어간 추출, stem=True : 단어의 기본형(어간)으로 변환, 형태소 추출
| 리스트 컴프리헨션의 기본 형식 [expression for item in iterable if condition] |
print(tokenized_data[0])
# 리뷰의 최대 길이와 리뷰의 평균 길이를 출력하기
print('리뷰의 최대 길이', max(len(review) for review in tokenized_data))
print('리뷰의 평균 길이', sum(map(len, tokenized_data)) / len(tokenized_data))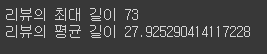
3. 워드 임베딩 구축
from gensim.models import Word2Vec
# 단어의 의미를 벡터 공간에 임베딩하여
# 비슷한 의미의 단어들이 가까운 벡터를 가지도록 학습하는 모델embeding_dim = 100
# sg: 0, 1(Skip-gram)
model = Word2Vec(
sentences = tokenized_data,
vector_size = embeding_dim,
window = 5,
min_count = 5,
workers = 4,
sg = 0
)# 임베딩 행렬의 크기
model.wv.vectors.shape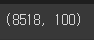
word_vectors = model.wv # 모델객체 저장
vocabs = list(word_vectors.index_to_key) # 단어 리스트
print(vocabs[:20])
for sim_word in model.wv.most_similar('영화'):
print(sim_word)most_similar() : 특정 단어와 가장 유사한 단어들을 찾는 데 사용

for sim_word in model.wv.most_similar('좋다'):
print(sim_word)
4. 워드 임베딩 시각화
import matplotlib.font_manager # 한글 폰트사용
import matplotlib.pyplot as plt
font_list = matplotlib.font_manager.findSystemFonts(fontpaths=None, fontext='ttf')
[matplotlib.font_manager.FontProperties(fname=font).get_name() for font in font_list if 'Nanum' in font]
plt.rc('font', family='NanumBarunGothic')
word_vector_list = [word_vectors[word] for word in vocabs]
word_vector_list[0]
import numpy as np
# PCA방식 : 차원축소 방식 알고리즘, 자주 이용되는 방식이긴 하지만 군집의 변별력을 해친다는 단점
# PCA를 개선한 방법이 t-SNE 차원 축소 방식
from sklearn.manifold import TSNE
# 고차원 데이터의 군집구조를 2,3차원 데이터로 시각화# n_components=2 : 2차원으로 변경, learning_rate(학습률) : 자동조절,
tsne = TSNE(n_components=2, learning_rate = 'auto', init = 'random')
transformed = tsne.fit_transform(np.array(word_vector_list))
# 고차원의 데이터를 저차원의 방식으로 전환x_axis_tsne = transformed[:, 0] # index 0열
y_axis_tsne = transformed[:, 1] # index 1열
print(x_axis_tsne)
print(y_axis_tsne)
def plot_tsne_graph(vocabs, x_axis, y_axis):
plt.figure(figsize=(30,30))
plt.scatter(x_axis, y_axis, marker='o')
for i, v in enumerate(vocabs):
plt.annotate(v, xy=(x_axis[i], y_axis[i]))
# annotate: 그래프에 해당하는 좌표의 점에 주석(v의 이름)달기annotate: 그래프에 해당하는 좌표의 점에 주석(v의 이름)달기
plot_tsne_graph(vocabs, x_axis_tsne, y_axis_tsne)
# vocabs : 시각화할 데이터(단어, 리스트)
# x_axis_tsne : x축 좌표
# y_axis_tsne : y축 좌표
5. TSNE 시각화 고도화
- 파이썬에서 제공하는 interactive visualization library인 Bokeh를 사용하여 시각화 고도화
- https://docs.bokeh.org/en/latest/
Bokeh documentation
Bokeh is a Python library for creating interactive visualizations for modern web browsers. It helps you build beautiful graphics, ranging from simple plots to complex dashboards with streaming data...
docs.bokeh.org
transformed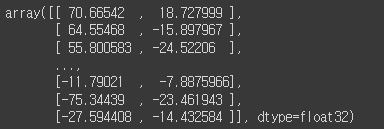
tsne_df = pd.DataFrame(transformed, columns=['x_coord', 'y_coord'])
tsne_df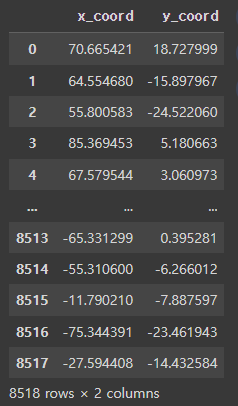
tsne_df['vocabs'] = vocabs # vocabs 데이터 column 추가 저장
tsne_df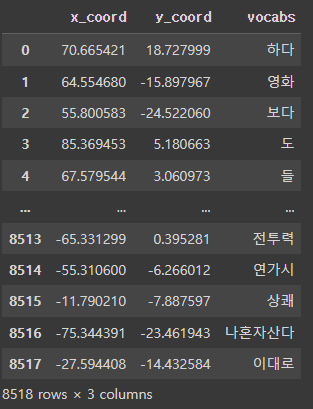
from bokeh.plotting import figure, show, output_notebook
from bokeh.models import HoverTool, ColumnDataSource
from bokeh.io import push_notebook
from bokeh.resources import INLINE
from bokeh.io import curdoc
# 한글 폰트 설정
import matplotlib.pyplot as plt
plt.rc('font', family='NanumGothic')
# Bokeh 출력 설정
output_notebook(resources=INLINE)
# prepare the data in a form suitable for bokeh.
plot_data = ColumnDataSource(tsne_df)
# create the plot and configure it
tsne_plot = figure(title='t-SNE Word Embeddings',
width = 800,
height = 800,
active_scroll='wheel_zoom'
)
# add a hover tool to display words on roll-over
tsne_plot.add_tools( HoverTool(tooltips = '@vocabs') )
tsne_plot.circle(
'x_coord', 'y_coord', source=plot_data,
color='red', line_alpha=0.2, fill_alpha=0.1,
size=10, hover_line_color='orange'
)
# adjust visual elements of the plot
tsne_plot.xaxis.visible = False
tsne_plot.yaxis.visible = False
tsne_plot.grid.grid_line_color = None
tsne_plot.outline_line_color = None
# show time!
show(tsne_plot);

'Python > 자연어처리' 카테고리의 다른 글
| Python(43)- cbow 분류 (0) | 2024.07.02 |
|---|---|
| Python(42)- RNN 기초 (0) | 2024.06.27 |
| Python(40)- 워드 임베딩 (0) | 2024.06.25 |
| Python(39)- 임베딩 (0) | 2024.06.25 |
| Python(38)- 자연어처리(NLP) 프로젝트 순서 (0) | 2024.06.25 |



