
*이 글을 읽기전에 작성자 개인의견이 있으니, 다른 블로그와 교차로 읽는것을 권장합니다.*
1. 워드 임베딩(Word Embedding)
- 단어를 컴퓨터가 이해하고 효율적으로 처리할 수 있도록 단어를 벡터화하는 기술
- 단어를 밀집 벡터의 형태로 표현하는 방법
- 워드 임베딩 과정을 통해 나온 결과를 임베딩 벡터라고 부름
- 워드 임베딩을 거쳐 잘 표현된 단어 벡터들은 계산이 가능하며, 모델에 입력으로 사용할 수 있음
1-1. 희소 표현(Sparse Representation)
- 원 핫 인코딩을 통해서 나온 벡터들은 표현하고자 하는 단어의 인덱스의 값만 1이고, 나머지 인덱스에 전부 0으로 표현되는 벡터 표현 방법에 의해 만들어지는 벡터를 희소 벡터라고 함
- Ex) 강아지 = [ 0 0 0 0 1 0 0 0 0 0 0 0 ... 중략 ... 0] # 이때 1 뒤의 0의 수는 9995개.
1-2. 희소 벡터의 문제점
- 희소 벡터의 특징은 단어의 개수가 늘어나면 벡터의 차원이 한없이 커진다는 것
- 원 핫 벡터는 벡터 표현 방식이 단순하여 단어의 출현 여부만을 벡터에 표시할 수 있음
- 희소 벡터를 이용하여 문장 혹은 텍스트간의 유사도를 계산해보면 원하는 유사도를 얻기 힘듬
1-3. 밀집 표현(Dense Representation)
- 벡터의 차원이 조밀해졌다는 의미
- 사용자가 설정한 값으로 모든 단어의 벡터 표현의 차원을 맞추는 표현 방식
- 자연어를 밀집 표현으로 변환하는 인코딩 과정에서 0과 1의 binary값이 아니라, 연속적인 실수 값을 가질 수 있음
- 적은 차원으로 대상을 표현할 수 있음
- 더 큰 일반화 능력을 가지고 있음
- Ex) 강아지 = [0.2 1.8 1.1 -2.1 1.1 2.8 ... 중략 ...] # 이 벡터의 차원은 128
1-4. 원 핫 벡터와 워드 임베딩의 차이
- 원 핫 벡터 : 고차원, 희소 벡터, 값의 유형이 0과 1
- 워드 임베딩 : 저차원, 밀집 벡터, 실수
1-5. 차원 축소(Dimensionality Reduction)
- 희소 벡터를 밀집 벡터의 형태로 변환하는 방법
- 머신러닝에서 많은 피쳐들로 구성된 고차원의 데이터에서 중요한 피쳐들만 뽑아 저차원의 데이터(행렬)로 변화하기 위해 사용
- PCA(Principal Component Analysis), 잠재 의미 분석(Latent Semantic Analysis), 잠재 디리클레 할당(Latent Dirichlet Allocation), SVD(Singular Value Decomposition)
2. 주요 워드 임베딩 알고리즘
- 워드 임베딩은 고차원의 단어 공간에서 저차원의 벡터 공간으로 변환하는 방법
- 변환된 벡터는 단어의 의미적 유사성을 반영하며, 유사한 의미를 가진 단어들은 벡터 공간에서 가깝게 위치
- 모델이 텍스트 데이터의 의미를 이해하고 학습할 수 있도록 함
2-1. Word2Vec
- 분포 가설 하에 표현한 분산 표현을 따르는 워드 임베딩 모델
- 분산 표현(Distributed Representation)
- 분포 가설: 비슷한 문맥에서 등장하는 단어들은 비슷한 의미를 가진다는 가설
- 분포 가설의 목표는 단어 주변의 단어들, window 크기에 따라 정의되는 문맥의 의미를 이용해 단어를 벡터로 표현하는 것
- 분산 표현으로 표현된 벡터들은 원 핫 벡터처럼 차원이 단어 집합의 크기일 필요가 없으므로 벡터의 차원이 상대적으로 저차원으로 줄어듬
- 희소 표현에서는 각각의 차원이 독립적인 정보를 가지고 있지만, 밀집에서는 하나의 차원이 여러 속성들이 버무려진 정보를 갖고 있음
- 분산 표현(Distributed Representation)
- 중심 단어와 주변의 단어들을 사용하여 단어를 예측하는 방식으로 임베딩을 만듦
- 구글이 2013년도 처음 공개
- Word2Vec의 학습 방식에는 CBOW(Continuous Bag of Words), Skip-Gram을 사용
- CBOW
- 주변에 있는 단어들을 보고 중간에 있는 단어를 예측하는 방법(주변단어->중심단어)
- 주변 단어(context)는 타겟 단어(target)의 직전 n개 단어와 직후 n개 단어를 의미하며, 이 범위를 window라 부르고, n을 window size라고 부름
- 문장 하나에 대해 한 번만 학습을 진행하면 데이터가 아깝기 때문에 sliding window 방식을 사용하여 하나의 문장을 가지고 여러 개의 학습 데이터셋을 만듦
- Skip-Gram
- 중심 단어에서 주변 단어를 예측 (중심단어->주변단어)
- 중심 단어를 sliding window 하면서 학습 데이터를 증강
- 중심 단어를 가지고 주변 단어를 예측하는 방법이기 때문에 window size의 2n개 만큼 학습 데이터가 나옴
- 장점 :
- 단어 간 문맥 정보를 효과적으로 학습할 수 있습니다.
- 희소 표현(sparse representation)보다 밀집 표현(dense representation)을 생성하므로 계산 효율성이 높습니다.
- CBOW vs Skip-gram
- Skip-gram이 CBOW에 비해 여러 문맥을 고려하기 때문에 Skip-gram의 성능이 일반적으로 더 좋음
- Skip-gram이 단어 당 학습 횟수가 더 많고, 임베딩의 조정 기회가 많으므로 더 정교한 임베딩 학습이 가능
- 작고 귀여운 강아지 문 앞에 앉아있다
- CBOW(window size=2)
- 귀여운, 강아지 -> 작고
- 작고, 강아지, 문 -> 귀여운
- 작고, 귀여운, 문, 앞에 -> 강아지
- 귀여운, 강아지, 앞에, 앉아있다 -> 문
- 강아지, 문, 앉아있다 -> 앞에
- 문, 앞에 -> 앉아있다
- Skip-gram
- 작고 -> 귀여운, 강아지
- 귀여운 -> 작고, 강아지, 문
- 강아지 -> 작고, 귀여운, 문, 앞에
- 문 -> 귀여운, 강아지, 앞에, 앉아있다
- 앞에 -> 강아지, 문, 앉아있다
- 앉아있다 -> 문, 앞에

- Word2Vec의 한계점
- 단어의 형태학적 특성을 반영하지 못함(예: torch, teacher, teachers와 같이 세 단어는 의미적으로 유사한 단어지만 각 단어를 개별단어로 처리)
- 단어 빈도 수의 영향을 많이 받아 희소한 단어를 임베딩하기 어려움
- OOV(Out of Vocabulary)의 처리가 어려움
- 새로운 단어가 등장하면 데이터 전체를 다시 학습시켜야 함
- 단어 사전의 크기가 클수록 학습하는데 오래걸림
- CBOW
2-2. FastText
- Facebook의 AI Research 팀에서 개발한 텍스트 분류 및 단어 벡터 표현 도구
- 대규모 데이터셋에서 빠르게 작동하도록 설계, 단어 임베딩과 텍스트 분류 모두에 사용할 수 있음
- 작동 원리
- <, >는 단어의 경계를 나타내기 위한 특수 기호
- 단어를 먼저 <, >로 감싼 후 설정한 n-gram의 값에 따라 앞에서부터 단어를 쪼갬
- 예) 'apple' ['a', 'ap', 'app', 'appl', 'apple', 'p', 'pp', 'ppl', 'ple', 'e']
- 마지막에 본 단어를 설명하기 위해 <, >으로 감싸진 전체 단어를 하나 추가함
- FastText 장점
- 오타나 모르는 단어에 대한 대응
- 단어 집합 내 변도 수가 적었던 단어에 대한 대응
- 자연어 코퍼스 내 노이즈에 대응
3. 워드 임베딩 구축하기
import pandas as pd
import numpy as np
from sklearn.datasets import fetch_20newsgroupsdataset = fetch_20newsgroups(shuffle=True, random_state=2024, remove = ('headers','footers', 'quotes'))
dataset = dataset.datadataset[0]
len(dataset)
# 컬럼명을 document로 한 데이터프레임을 만들기
news_df = pd.DataFrame({'document':dataset})
news_df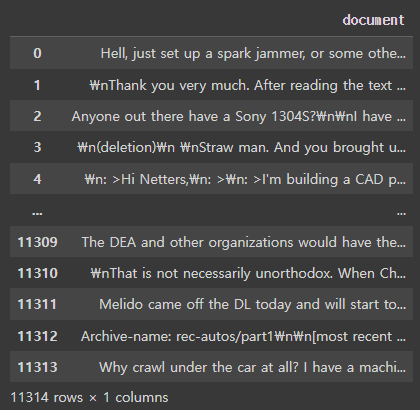
# 데이터셋에서 결측값이 있다면 제거, 총 데이터셋의 개수를 출력
news_df = news_df.dropna().reset_index(drop=True)
len(news_df)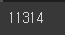
# 중복된 데이터가 있다면 제거
processed_news_df = news_df.drop_duplicates(['document']).reset_index(drop=True)
len(processed_news_df)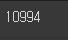
# 데이터셋의 데이터 중 특수문자를 제거
def remove_special_characters(text):
import re
return re.sub(r'[^\w\s]', '', text)
processed_news_df['document'] = processed_news_df['document'].str.replace('[^a-zA-Z0-9]', ' ', regex=True)
processed_news_df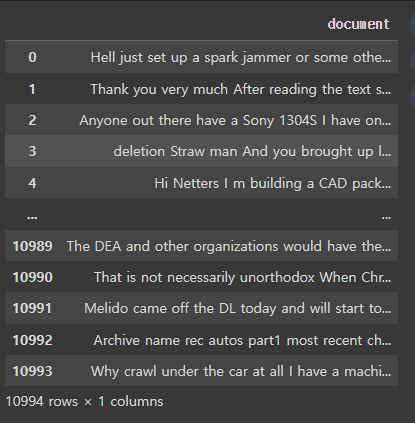
# 데이터셋의 길이가 너무 짧은 단어를 제거(단어의 길이는 2이하)
processed_news_df['document'] = processed_news_df['document'].apply(lambda x: ' '.join([token for token in x.split() if len(token)>2]))
processed_news_df
# 전체 문장이 100자이상이고 단어의 갯수가 3개 이상인 데이터만 필터링
processed_news_df = processed_news_df[processed_news_df.document.apply(lambda x: len(str(x)) >= 100 and len(str(x).split()) >= 3)].reset_index(drop=True)
processed_news_df
# 전체 단어에 대해 소문자로 변환
processed_news_df['document'] = processed_news_df['document'].apply(lambda x: x.lower())
processed_news_df
import nltk # 자연어처리
from nltk.corpus import stopwords # 코퍼스를 활용하여 자연어처리nltk :
- 텍스트 전처리:
- 문장 토큰화(Sentence Tokenization)
- 단어 토큰화(Word Tokenization)
- 불용어(Stopwords) 제거
- 어간 추출(Stemming) 및 표제어 추출(Lemmatization)
- 품사 태깅(Part-of-Speech Tagging)
- 단어의 품사 정보 추출
- 개체명 인식(Named Entity Recognition)
- 문서 내의 사람, 장소, 조직 등 개체명 식별
- 감성 분석(Sentiment Analysis)
- 텍스트의 긍정/부정 감성 판단
- 문서 분류(Text Classification)
- 기계 학습 알고리즘을 활용한 문서 분류
- 문서 요약(Text Summarization)
- 핵심 내용 추출을 통한 문서 요약
- 단어 관계 분석(Word Relationships)
- 유의어, 반의어, 상위어 등 단어 관계 파악
nltk.download('stopwords')
stop_words = stopwords.words('english')
print(len(stop_words))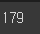
# 데이터셋에서 불용어를 제외하고, 띄어쓰기 단위로 문장을 분리하여 리스트로 저장
# [hell, set, spark, jammer, electrically, noisy ...]
tokenized_doc = processed_news_df['document'].apply(lambda x: x.split())
tokenized_doc = tokenized_doc.apply(lambda x: [s_word for s_word in x if s_word not in stop_words])
tokenized_doc
len(tokenized_doc)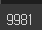
from tensorflow.keras.preprocessing.text import Tokenizer
# tensorflow.keras -> 텍스트데이터 수치화
# 토큰화
tokenizer = Tokenizer()
# 텍스트 데이터 -> tokenizer 학습
tokenizer.fit_on_texts(tokenized_doc)word2idx = tokenizer.word_index
print(word2idx)
# 키 -> value, value -> 키
idx2word ={value: key for key, value in word2idx.items()}
print(idx2word)
encoded = tokenizer.texts_to_sequences(tokenized_doc)
print(encoded[0])
vocab_size = len(word2idx)
print(f'단어사전의 크기: {vocab_size}')
# 텍스트 데이터를 다루는 과정에서 단어 쌍을 생성하는 데 사용
# Skip-gram 모델을 사용하여 단어 쌍을 만들며, Word2Vec 알고리즘의 구성 요소
# 주어진 단어를 기준으로 주변 단어를 예측하는 방식으로 단어 벡터를 학습
from tensorflow.keras.preprocessing.sequence import skipgrams# skipgrams(시퀀스, 사전크기, 윈도우크기)
# 시퀀스 : 인코딩한 리스트 -> 5개
# 사전크기 : 단어사전의 크기, 시퀀스에 등장하는 단어의 총 갯수 = 97004
# 중심단어와 주변단어간의 최대 거리
skip_grams = [skipgrams(sample, vocabulary_size=vocab_size, window_size=10) for sample in encoded[:5]]
print(f'전체 샘플 수: {len(skip_grams)}')
# skipgrams 함수가 (중심 단어, 주변 단어) 쌍을 생성할 때 무작위성을 도입하기 때문
# 중심 단어와 주변 단어 쌍을 랜덤하게 선택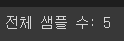
# 부정적 예 : 중심단어와 실제 텍스트에서 함께 등장하지 않은 단어(0) -> 나올 수 없음
# 긍정적 예 : 실제 텍스트에서 중심단어와 주변단어가 함께 등장한 경우(1) -> 등장
# pairs : (중심단어, 주변단어) 형태의 단어 쌍 리스트
# labels: 각 단어 쌍의 레이블 리스트로, 해당 단어 쌍이 실제로 등장하는지 여부를 나타냄
pairs, labels = skip_grams[0][0], skip_grams[0][1]
print(pairs)
print(labels)
# 단어간의 쌍을 맺었을 때, [341, 53805] - 0번, [24674, 4757] - 1번
print(len(pairs))
print(len(labels))
# pairs와 labels의 값이 동일 -> 대응됨
for i in range(5):
print('({:s}({:d}), {:s}({:d})) -> {:d}'.format(
idx2word[pairs[i][0]], pairs[i][0],
idx2word[pairs[i][1]], pairs[i][1],
labels[i]
))
training_dataset = [skipgrams(sample, vocabulary_size = vocab_size, window_size = 10) for sample in encoded[:9981]]
len(training_dataset)
# Sequential : layer(층) 쌓아올리는 모델 구현
from tensorflow.keras.models import Sequential, Model
# Embedding : 인코딩된 단어를 밀집 벡터로 변환하는 임베딩 레이어
# Reshape : 입력 데이터의 형상을 변경하는 레이어
# Activation : 활성화 함수를 적용하는 레이어
# Input: 모델의 입력 레이어를 정의하는 레이어
# Dot : 두 텐서 간의 내적 연산을 수행하는 레이어
from tensorflow.keras.layers import Embedding, Reshape, Activation, Input, Dot
# Keras 모델의 구조를 이미지 파일로 저장
from tensorflow.keras.utils import plot_modelembedding_dim = 100 # 100차원
# 모델 만들때 2개 입력, 단어는 100차원으로 임베딩, 단어테이블 -> 100개로 max 설정 후 저장
# 행렬은 내적 (Dot product) 계산
# shape=(1,) 1개의 데이터 index, 입력받을 레이어 -> w_inputs
w_inputs = Input(shape=(1,), dtype='int32')
# word 리턴
word_embedding = Embedding(vocab_size, embedding_dim)(w_inputs)
# context 리턴
c_inputs = Input(shape=(1,), dtype='int32')
context_embedding = Embedding(vocab_size, embedding_dim)(c_inputs)dot_product = Dot(axes=2)([word_embedding, context_embedding]) # 두 임베딩 단어의 내적으로 Dot Product 계산, 100차원
dot_product = Reshape((1,), input_shape=(1, 1))(dot_product) # 1열, 데이터형태: 1x1 -> 열벡터
output = Activation('sigmoid')(dot_product) # 1~0사이의 값(시그모이드 출력값)으로 리턴
model = Model(inputs=[w_inputs, c_inputs], outputs=output)
model.summary() # 모델 모양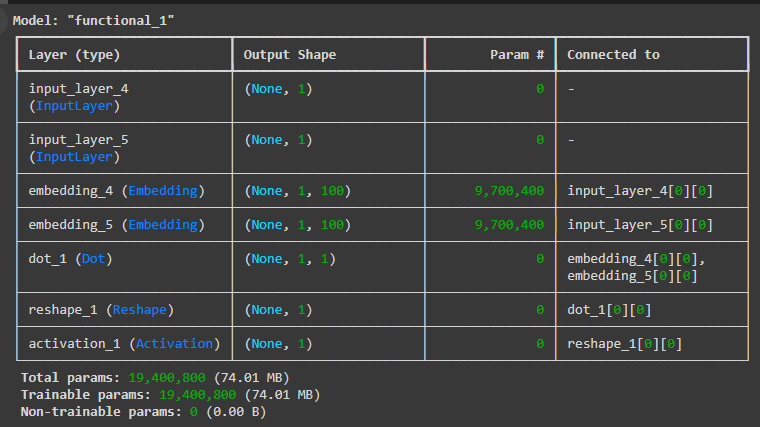
# 실제 모델을 돌리기 전, 손실함수와 optimizer를 선택해야함
# 손실함수 = 이진교차엔트로피
# optimizer = adam : 최적화로 adam 사용
model.compile(loss='binary_crossentropy', optimizer='adam')plot_model(model, to_file='model.png', show_shapes=True, show_layer_names=True)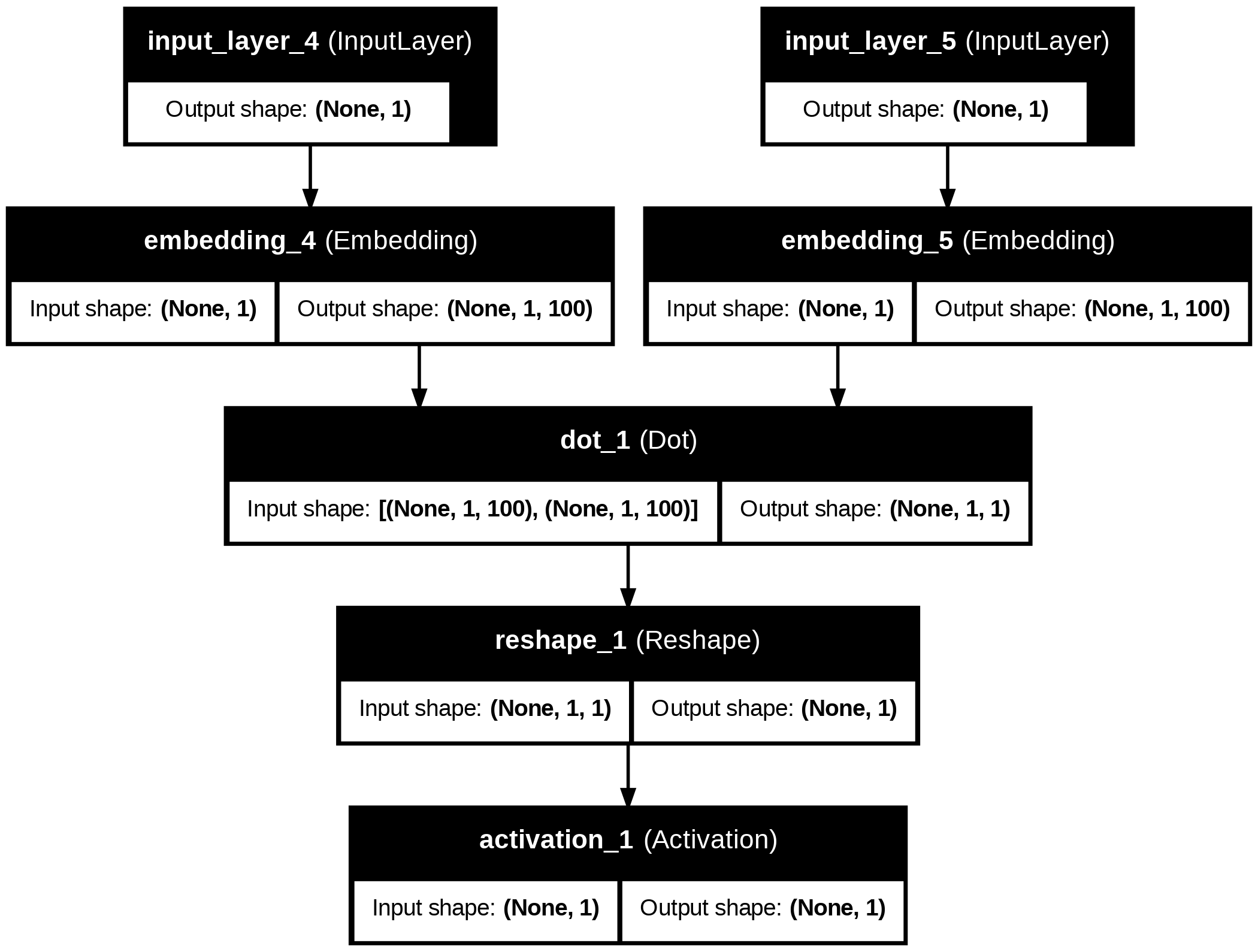
for epoch in range(100):
loss = 0
# for _, elem in enumerate(training_dataset):
for _, elem in enumerate(skip_grams):
first_elem = np.array(list(zip(*elem[0]))[0], dtype='int32')
second_elem = np.array(list(zip(*elem[0]))[1], dtype='int32')
labels = np.array(elem[1], dtype='int32')
X = [first_elem, second_elem]
y = labels
loss += model.train_on_batch(X, y)
print('Epoch:', epoch+1, 'Loss', loss)
# Gensim
# 자연어처리 작업에서 주로 사용되는 오픈소스 라이브러리
# 토픽, 모델링, 문서 유사도 계산, 단어 임베딩(Word2Vec, FastText등)
import gensimvectors = model.get_weights()[0]
vectors
len(vectors)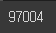
f = open('vectors.txt', 'w')
f.write('{} {}\n'.format(vocab_size, embedding_dim))
for word, i in tokenizer.word_index.items():
f.write('{} {}\n'.format(word, ' '.join(map(str, list(vectors[i-1, :])))))
f.close()w2v = gensim.models.KeyedVectors.load_word2vec_format('./vectors.txt', binary=False)
# binary=False : 이 옵션은 임베딩 벡터 파일이 텍스트 형식으로 저장# flower 과 유사한 단어 찾기
w2v.most_similar(positive=['flower'])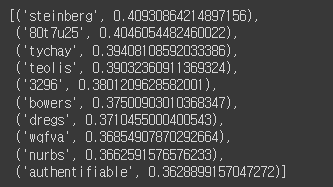
w2v.most_similar(positive=['apple'])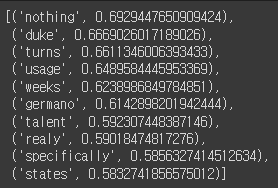
'Python > 자연어처리' 카테고리의 다른 글
| Python(42)- RNN 기초 (0) | 2024.06.27 |
|---|---|
| Python(41)- 워드 임베딩 시각화 (0) | 2024.06.27 |
| Python(39)- 임베딩 (0) | 2024.06.25 |
| Python(38)- 자연어처리(NLP) 프로젝트 순서 (0) | 2024.06.25 |
| Python(37)- 자연어 처리(NLP) (0) | 2024.06.25 |



