
*이 글을 읽기전에 작성자 개인의견이 있으니, 다른 블로그와 교차로 읽는것을 권장합니다.*
1. 자연어의 특성
- 자연어를 기계가 처리하도록 하기 위해서는 먼저 자연어를 기계가 이해할 수 있는 언어로 바꾸는 방법을 알아야 합니다.
- 토큰화 작업의 결과인 단어 사전을 기계가 이해할 수 있는 언어로 표현하는 과정이고, 단어 사전 내 단어 하나를 어떻게 표현할까의 문제로 볼 수 있습니다.
1-1. 단어의 유사성과 모호성
- 단어의 의미는 유사성과 모호성을 가지고 있는데 단어는 겉으로 보이는 형태인 표제어안에 여러가지 의미를 담고 있습니다.
- 사람은 주변 정보에 따라 숨겨진 의미를 파악하고 이해할 수 있으나 ,기계는 학습의 부재 또는 잘못된 데이터로 의미를 파악하지 못하는 경우가 많습니다.
- 한 가지 형태의 단어에 여러 의미가 포함되어 생기는 중의성 문제는 자연어 처리에서 매우 중요
- 동형어 : 형태는 같으나 뜻이 서로 다른 단어(예: 배)
- 다의어 : 하나의 형태가 여러 의미를 지니면서도 그 의미들이 서로 관련이 있는 단어(예: 머리)
- 동의어 : 서로 다른 형태의 단어들이 동일한 의미를 가지는 단어(예: 춘추, 나이)
- 상의어 : 상위 개념을 가리키는 단어(예: 동물)
- 하의어 : 하위 개념을 가리키는 단어(예: 강아지)
1-2. 언어의 모호성 해소
- 동형어나 다의어처럼 여러 의미를 가지는 단어들이 하나의 형태로 공유, 동의어처럼 하나의 형태를 가지는 단어들이 서로 같은 의미를 공유
- 단어 중의성 해소(WSD) 알고리즘 방법을 통해 단어의 의미를 명확히 할 필요
- 지식 기반 단어 중의성 해소
- 컴퓨터가 읽을 수 있는 사전이나 어휘집 등을 바탕으로 단어의 의미를 추론하는 접근 방식
- 사람이 직접 선별해서 데이터를 넣으므로 노이즈가 적다
- 구축에 많은 리소스 필요
- 데이터 편향이 생길 수 있다
- 지도 학습 기반 단어 중의성 해소
- 지도 학습은 데이터에 정답이 있다는 의미로, 각종 기계 학습 알고리즘을 통해 단어 의미를 분류해내는 방법
- 좋은 성능을 위해서는 질 높은 레이블을 가진 많은 데이터가 필요
- 데이터가 충분할 경우 일반화된 환경에서도 좋은 성능을 낼 수 있다
- 비지도 학습 기반 단어 중의성 해소
- 문장에 등장하는 각 단어의 의미를 사전적인 의미에 연결하지 않고, 세부의미가 같은 맥락을 군집화하는 데에 초점을 맞춤
- 대규모 자연어 코퍼스로부터 추가 작업 없이 자동적으로 학습을 수행할 수 있어서 활용 가능성이 높다
- 사람이 직접 제작한 학습 데이터를 사용하지 않기 때문에 성능을 내기 어려움
- 지식 기반 단어 중의성 해소
2. 임베딩 구축방법
2-1. 임베딩
- 자연어처리 작업에서 특징 추출을 통해 자연어를 수치화하는 과정이 필요하고 이런 벡터화의 과정이자 결과
- 토큰화 작업의 목표는 임베딩을 만들기 위한 단어 사전을 구축하는 것
2-2. 임베딩의 역할
- 자연어의 의미적인 정보 함축
- 자연어의 중요한 특징들을 추출하여 벡터로 압축하는 과정
- 임베딩으로 표현된 문장은 실제 자연어의 주요 정보들을 포함하고 있음
- 벡터인만큼 사칙 연산이 가능하여 단어 벡터간 덧셈/뺄셈을 통해 단어들 사이의 의미적 문법적 관계를 도출
- 임베딩의 품질을 평가하기 위해 사용되는 단어 유추 평가(https://word2vec.kr/search/)
- 자연어간의 유사도 계산
- 자연어를 벡터로 표현하면 두 벡터간의 유사도를 계산할 수 있음(코사인 유사도, 유클리디안 거리 기반 유사도, 맨하탄 거리 기반 유사도 ...)
- 코사인 유사도는 -1이상 1이하의 값을 가지며, 값이 1에 가까울수록 유사도가 높다고 판단
- 전이 학습
- 이미 만들어진 임베딩을 다른 작업을 학습하기 위한 입력값으로 쓰임
- 품질 좋은 임베딩을 사용할수록 목표로 하는 자연어처리 작업의 학습속도와 성능이 향상됨
- 매번 새로운 것을 배울때 scratch부터 시작한다면 매 학습마다 오래걸림
- 파인 튜닝 : 학습하는데 전이학습에 의한 임베딩을 초기화하여 사용하면 새로운 작업을 학습함에도 빠르게 학습할 수 있고 성능도 좋아짐
2-3. 단어 출현 빈도에 기반한 임베딩 구축방법
- 원 핫 인코딩
- 자연어를 0과 1로 구별하겠다는 인코딩 방법
- 표현하고 싶은 단어의 인덱스에 1의 값을 부여하고, 나머지 인덱스에는 0을 부여하는 벡터 표현방식
- ".. 오늘 날씨가 참 좋다.." -> {...5: '좋다', 6:'날씨', ... '13:'오늘', ... 257:'가',...} (일반적으로 빈도수로 정렬하고 사용, 인덱스의 순서가 의미가 없음)
- 순서가 없는 카테고리컬 피쳐인 경우 클래스 갯수가 3개 이상일 때, 원 핫 인코딩을 함
- '오늘 좋아 내일 싫어'
- 오늘 -> [1, 0, 0, 0]
- 좋아 -> [0, 1, 0, 0]
- 내일 -> [0, 0, 1, 0]
- 싫어 -> [0, 0, 0, 1]
- 단어 사전의 크기가 10,000이라면, 총 10,000개 중 현재 단어를 표현하는 1개의 차원에만 1을, 나머지 9,999개의 차원은 0으로 표현
- 대부분의 값들이 0인 행렬을 희소행렬이라 하는데, 단어가 늘어날수록 행렬의 크기는 계속 증가하나, 증가하는 크기에 비해 표현의 효율성이 떨어짐
- 단어의 유사도를 표현하지 못함
- Bag of Words
- 단어들의 순서를 전혀 고려하지 않고 단어들의 출현빈도에 집중하는 자연어코퍼스의 데이터 수치화 방법
- 각 단어에 고유한 정수 인덱스를 부여하여 단어 집합을 생성하고 각 인덱스의 위치에 단어 토큰의 등장 횟수를 기록한 벡터를 만듦
- 단어 단위 압축 방식이기 때문에 희소 문제와 단어 순서를 반영하지 못함
- 문장을 표현하는 방법 -> 원 핫 인코딩을 모두 더함
- 오늘 좋아 : [1, 1, 0, 0]
- 오늘 좋아 좋아 : [1, 2, 0, 0]
- 오늘 싫어 : [1, 0, 0, 1]
- 오늘 좋아 내일 싫어 : [1, 1, 1, 1]
- 오늘 싫어 내일 좋아 : [1, 1, 1, 1]
- TF-IDF
- 단어의 빈도와 문서의 빈도를 사용하여 문서-단어 행렬 내 각 단어들의 중요한 정도를 가중치로 주는 표현 방법
- 문서의 유사도를 구하는 작업, 검색 시스템에서 검색 결과의 중요도를 정하는 작업, 문서 내에서 특정 단어의 중요도를 구하는 작업 등에서 효과적으로 쓰일 수 있음
2-4. 단어의 순서
- 통계 기반 언어 모델
- 단어가 n개 주어졌을 때 언어 모델은 n개의 단어가 동시에 나타날 확률을 변환
- 문장은 어순을 고려하여 여러 단어로 이루어진 단어 시퀀스라고 부르며 n개의 단어로 구성된 단어 시퀀스를 확률적으로 표현
- 딥러닝 기반 언어 모델
- 통계 기반 언어 모델에서는 빈도라는 통계량을 활용하여 확률을 추산하여 나열하지만, 딥러닝 기반 언어 모델들이 등장하면서 입력과 출력 사이의 관계를 유연하게 정의할 수 있게 되고, 그 자체로 확률 모델로 동작할 수 있음
- MLM(Masked Language Modeling)
- 문장 중간에 마스크를 씌워서 해당 마스크에 어떤 단어가 올지 예측하는 과정으로 학습을 진행
- 문장 전체를 다 보고 중간에 있는 단어를 예측하기 때문에 양방향 학습이 가능
- 대표적으로 BERT 모델이 있음
- Next Token Prediction
- 주어진 단어 시퀀슬르 가지고 다음 단어로 어떤 단어가 올지 에측하는 과정으로 학습
- 단어를 순차적으로 입력받은 뒤 다음 단어를 맞춰야하기 때문에 한방향 학습을 함
- 대표적으로 GPT, ELMo 모델이 있음
3. 텍스트 유사도
- 두 개의 자연어 텍스트가 얼마나 유사한지를 나타내는 방법
- 유사도를 정의하거나 판단하는 척도가 주관적이기 때문에, 최대한 정량화하는 방법을 찾는 것이 중요
3-1. 유클리디안 거리기반 유사도
- 두 점 사이의 거리를 측정하는 유클리디안 거리 공식을 사용하여 문서의 유사도를 구하는 방법으로 거리가 가까울수록 유사도가 높다고 판단
- 자연어처리 분야뿐 아니라 다른 분야에서도 범용적으로 사용되는 거리 측정기법
3-2. 맨하탄 거리 기반 유사도
- 맨하탄 거리 공식을 사용하여 문서의 유사도를 구하는 방법
- 유클리드 거리 공식과 유사하나 각 차원의 차를 곱해서 사용하는 대신 절대값을 바로 합산함
- 유클리드 거리 공식보다 값이 크거나 같음
- 다차원 공간상에서 두 좌표간의 최단거리를 구하는 방법이 아니다보니 특별한 상황이 아니면 잘 사용되지 않음
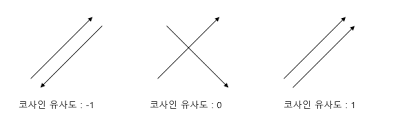
3-3. 코사인 유사도
- 두개의 벡터값에서 코사인 각도를 이용하여 구할 수 있는 두 벡터의 유사도를 의미
- 두 벡터의 방향이 완전히 동일한 경우는 1의 값을 가지며, 90도의 각을 이루면 0, 180도로 반대의 방향을 가지면 -1의 값을 가짐
- -1 이상 1 이하의 값을 가지며, 값이 1에 가까울수록 유사하다는 것을 의미
- 두 벡터가 가리키는 방향이 얼마나 유사한가를 의미하기 때문에 자연어 내 유사도 계산에 적합함
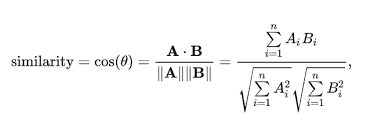
3-4. 자카드 유사도
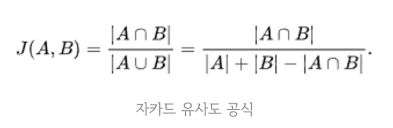
- 두 문장을 각각 단어의 집합으로 만든 뒤 두 집합을 통해 유사도를 측정하는 방식
- 수치화된 벡터 없이 단어 집합만으로 계산할 수 있음
- 두 집합의 교집합인 공통된 단어의 개수를 두 집합의 합집합을 전체 단어의 개수로 나눈 것
- 전체 합집합 중 공통의 단어의 개수에 따라 0과 1사이의 값을 가지며, 1에 가까울수록 유사도 높음
실습
sen_1 = '오늘 점심에 배가 너무 고파서 밥을 너무 많이 먹었다'
sen_2 = '오늘 점심에 배가 고파서 밥을 많이 먹었다'
sen_3 = '오늘 배가 너무 고파서 점심에 밥을 너무 많이 먹었다'
sen_4 = '오늘 점심에 배가 고파서 지하철을 많이 먹었다'
sen_5 = '어제 저녘에 밥을 너무 많이 먹었더니 배가 부르다'
sen_6 = '이따가 오후 6시에 출발하는 비행기가 3시간 연착 되었다고 하네요'training_documents = [sen_1, sen_2, sen_3, sen_4, sen_5, sen_6]
for text in training_documents:
print(text)
from sklearn.feature_extraction.text import CountVectorizer
# 텍스트 -> 수치형 벡터 변환
vectorizer = CountVectorizer()
vectorizer.fit(training_documents)
word_idx = vectorizer.vocabulary_
word_idx
# word_idx를 idx 순서대로 정렬
for key, idx in sorted(word_idx.items()):
print(f'{key}: {idx}')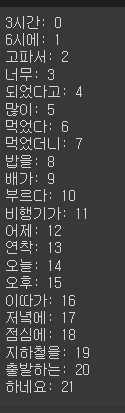
# word_idx에 따라 dataframe을 생성
# column : key, index : 문장idx, 값: 빈도수
import pandas as pd
result = []
vocab = list(word_idx.keys())
# vocab
for i in range(len(training_documents)):
result.append([])
d = training_documents[i]
for j in range(len(vocab)):
target = vocab[j]
result[-1].append(d.count(target))
tf = pd.DataFrame(result, columns=vocab)
tf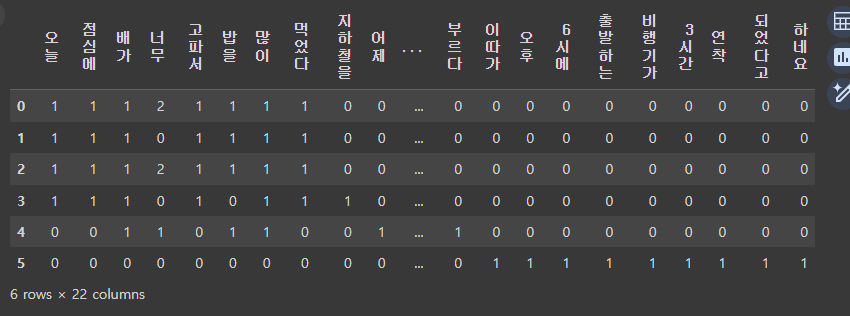
vector_sen_1 = vectorizer.transform([sen_1]).toarray()[0]
vector_sen_2 = vectorizer.transform([sen_2]).toarray()[0]
vector_sen_3 = vectorizer.transform([sen_3]).toarray()[0]
vector_sen_4 = vectorizer.transform([sen_4]).toarray()[0]
vector_sen_5 = vectorizer.transform([sen_5]).toarray()[0]
vector_sen_6 = vectorizer.transform([sen_6]).toarray()[0]
print(vector_sen_1)
print(vector_sen_2)
print(vector_sen_3)
print(vector_sen_4)
print(vector_sen_5)
print(vector_sen_6)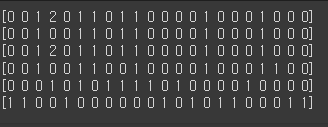
# 코사인 기반 유사도 계산
import numpy as np
from numpy import dot # dot product 사용
from numpy.linalg import norm # norm 사용
def cos_sim(A, B):
return dot(A, B) / (norm(A) * norm(B))| sen_1 = '오늘 점심에 배가 너무 고파서 밥을 너무 많이 먹었다' sen_2 = '오늘 점심에 배가 고파서 밥을 많이 먹었다' sen_3 = '오늘 배가 너무 고파서 점심에 밥을 너무 많이 먹었다' sen_4 = '오늘 점심에 배가 고파서 지하철을 많이 먹었다' sen_5 = '어제 저녘에 밥을 너무 많이 먹었더니 배가 부르다' sen_6 = '이따가 오후 6시에 출발하는 비행기가 3시간 연착 되었다고 하네요' |
print(f'sen_1, sen_2: {cos_sim(vector_sen_1, vector_sen_2)}')
print(f'sen_1, sen_3: {cos_sim(vector_sen_1, vector_sen_3)}')
print(f'sen_2, sen_4: {cos_sim(vector_sen_2, vector_sen_4)}')
print(f'sen_1, sen_5: {cos_sim(vector_sen_1, vector_sen_5)}')
print(f'sen_1, sen_6: {cos_sim(vector_sen_1, vector_sen_6)}')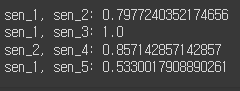
- sen_1, sen_2 : 의미가 유사한 문장 간 유사도 계산(조사 생략) -> 0.7977240352174656
- sen_1, sen_3 : 의미가 유사한 문장 간 유사도 계산(순서 변경) -> 1.0
- sen_2, sen_4 : 문장 내 단어를 임의의 단어로 치환한 문장과 원 문장 간 유사도 계산 -> 0.857142857142857
- sen_1, sen_5 : 의미는 다르지만 비슷한 주제를 가지는 문장 간 유사도 계산 -> 0.5330017908890261
- sen_1, sen_6 : 의미가 서로 다른 문장 간 유사도 계산 -> 0.5330017908890261
# TF-IDF기반 행렬을 활용한 문장 간 유사도 측정
from sklearn.feature_extraction.text import TfidfVectorizer
tfidfv = TfidfVectorizer().fit(training_documents)
for key, idx in sorted(tfidfv.vocabulary_.items()):
print(f'{key}:{idx}')
tf_idf = tfidfv.transform(training_documents).toarray()
print(tf_idf)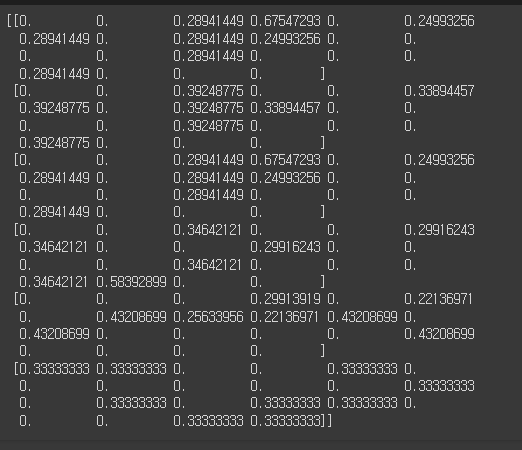
# TF-IDF 행렬에서 얻어지는 유사도의 값을 0 ~ 1로 스케일하기 위해 L1정규화를 진행
def l1_normalize(v):
norm = np.sum(v)
return v / normtfidf_vectorizer = TfidfVectorizer()
tfidf_matrix_l1 = tfidf_vectorizer.fit_transform(training_documents)
tfidf_norm_l1 = l1_normalize(tfidf_matrix_l1)
tfidf_norm_l1
tf_sen_1 = tfidf_norm_l1[0:1]
tf_sen_2 = tfidf_norm_l1[1:2]
tf_sen_3 = tfidf_norm_l1[2:3]
tf_sen_4 = tfidf_norm_l1[3:4]
tf_sen_5 = tfidf_norm_l1[4:5]
tf_sen_6 = tfidf_norm_l1[5:6]
tf_sen_1.toarray()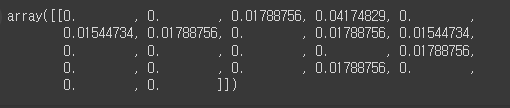
# 유클리디안 거리 기반 유사도 측정
from sklearn.metrics.pairwise import euclidean_distances
euclidean_distances(tf_sen_1, tf_sen_2)
# 거리구하는 공식 직접만들기
def euclidean_distances_value(vec_1, vec_2):
return round(euclidean_distances(vec_1, vec_2)[0][0], 3)print(f'sen_1, sen_2: {euclidean_distances_value(tf_sen_1, tf_sen_2)}')
print(f'sen_1, sen_3: {euclidean_distances_value(tf_sen_1, tf_sen_3)}')
print(f'sen_2, sen_4: {euclidean_distances_value(tf_sen_2, tf_sen_4)}')
print(f'sen_1, sen_5: {euclidean_distances_value(tf_sen_1, tf_sen_5)}')
print(f'sen_1, sen_6: {euclidean_distances_value(tf_sen_1, tf_sen_6)}')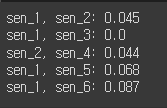
# 맨하탄 유사도
from sklearn.metrics.pairwise import manhattan_distances
def manhattan_distances_value(vec_1, vec_2):
return round(manhattan_distances(vec_1, vec_2)[0][0], 3)print(f'sen_1, sen_2: {manhattan_distances_value(tf_sen_1, tf_sen_2)}')
print(f'sen_1, sen_3: {manhattan_distances_value(tf_sen_1, tf_sen_3)}')
print(f'sen_2, sen_4: {manhattan_distances_value(tf_sen_2, tf_sen_4)}')
print(f'sen_1, sen_5: {manhattan_distances_value(tf_sen_1, tf_sen_5)}')
print(f'sen_1, sen_6: {manhattan_distances_value(tf_sen_1, tf_sen_6)}')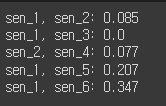
# 코사인 유사도
from sklearn.metrics.pairwise import cosine_similarity
def cosine_similarity_value(vec_1, vec_2):
return round(cosine_similarity(vec_1, vec_2)[0][0], 3)print(f'sen_1, sen_2: {cosine_similarity_value(tf_sen_1, tf_sen_2)}')
print(f'sen_1, sen_3: {cosine_similarity_value(tf_sen_1, tf_sen_3)}')
print(f'sen_2, sen_4: {cosine_similarity_value(tf_sen_2, tf_sen_4)}')
print(f'sen_1, sen_5: {cosine_similarity_value(tf_sen_1, tf_sen_5)}')
print(f'sen_1, sen_6: {cosine_similarity_value(tf_sen_1, tf_sen_6)}')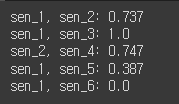
# 언어 모델을 활용한 문장 간 유사도 측정
!pip install transformers
# AutoModel, AutoTokenizer, BertTokenizer
from transformers import AutoModel, AutoTokenizer, BertTokenizerAutomodel : 사전 훈련된 모델을 자동으로 로드할 수 있도록 설계된 클래스
AutoTokenizer : 텍스트를 모델이 이해할 수 있는 형식으로 변환, 입력 텍스트를 토큰화하여 입력 ID로 변환
BertTokenizer : BERT 모델의 입력 형식에 맞게 텍스트를 토큰화하고, 패딩, 어텐션 마스크 등을 처리
MODEL_NAME = 'bert-base-multilingual-cased'
model = AutoModel.from_pretrained(MODEL_NAME)
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
bert_sen_1 = tokenizer(sen_1, return_tensors='pt') # 파이토치 텐서 자료구조로 변환
bert_sen_2 = tokenizer(sen_2, return_tensors='pt')
bert_sen_3 = tokenizer(sen_3, return_tensors='pt')
bert_sen_4 = tokenizer(sen_4, return_tensors='pt')
bert_sen_5 = tokenizer(sen_5, return_tensors='pt')
bert_sen_6 = tokenizer(sen_6, return_tensors='pt')
bert_sen_1
sen_1_outputs = model(**bert_sen_1)
# pooler_output : BERT모델에서 나온 마지막 레이어의 출력 값
sen_1_pooler_output = sen_1_outputs.pooler_output
sen_2_outputs = model(**bert_sen_2)
sen_2_pooler_output = sen_2_outputs.pooler_output
sen_3_outputs = model(**bert_sen_3)
sen_3_pooler_output = sen_3_outputs.pooler_output
sen_4_outputs = model(**bert_sen_4)
sen_4_pooler_output = sen_4_outputs.pooler_output
sen_5_outputs = model(**bert_sen_5)
sen_5_pooler_output = sen_5_outputs.pooler_output
sen_6_outputs = model(**bert_sen_6)
sen_6_pooler_output = sen_6_outputs.pooler_outputfrom torch import nn
cos_sim = nn.CosineSimilarity(dim=1, eps=1e-6)
print(f'sen_1, sen_2: {cos_sim(sen_1_pooler_output, sen_2_pooler_output)}')
print(f'sen_1, sen_3: {cos_sim(sen_1_pooler_output, sen_3_pooler_output)}')
print(f'sen_2, sen_4: {cos_sim(sen_2_pooler_output, sen_4_pooler_output)}')
print(f'sen_1, sen_5: {cos_sim(sen_1_pooler_output, sen_5_pooler_output)}')
print(f'sen_1, sen_6: {cos_sim(sen_1_pooler_output, sen_6_pooler_output)}')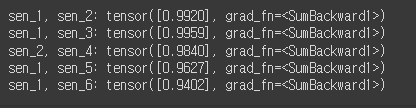
'Python > 자연어처리' 카테고리의 다른 글
| Python(42)- RNN 기초 (0) | 2024.06.27 |
|---|---|
| Python(41)- 워드 임베딩 시각화 (0) | 2024.06.27 |
| Python(40)- 워드 임베딩 (0) | 2024.06.25 |
| Python(38)- 자연어처리(NLP) 프로젝트 순서 (0) | 2024.06.25 |
| Python(37)- 자연어 처리(NLP) (0) | 2024.06.25 |



